
为了克服内存限制并使更大的大型语言模型(7B+参数)能够在浏览器中运行,Google AI Edge团队重新设计了模型加载代码,推出了跨平台推理框架。
大型语言模型(LLMs)为人类与计算机和设备的互动带来了新的可能性。尽管这些模型通常运行在专用服务器上,通过网络连接传输请求和响应,但在设备上完全运行模型是一种有吸引力的替代方案。这种方式不仅可以消除服务器成本,还能提供更高的用户隐私保护,并支持离线使用。然而,由于LLMs通常包含数十亿参数、文件大小以GB计,因此在设备上运行这些模型对机器学习基础设施是一个巨大的考验,容易导致内存和计算资源超载。
今年早些时候,Google AI Edge的MediaPipe框架推出了一款实验性的跨平台LLM推理API,该API可以利用设备GPU在Android、iOS和Web上高效运行小型LLMs,最大限度提升性能。最初,这一系统支持在设备上完全运行四款公开可用的LLMs:Gemma、Phi 2、Falcon和Stable LM。这些模型的参数规模从1亿到30亿不等。
当时,30亿参数是该系统能够在浏览器中运行的最大模型。为了实现广泛的跨平台覆盖,Google的系统首先针对移动设备进行优化,随后升级以支持浏览器运行。这次升级虽然保留了速度优势,但由于浏览器的内存限制,使用和内存管理的复杂性也随之增加。加载更大的模型会突破这些内存限制。此外,由于系统需要支持多种模型并使用单文件的.tflite格式,Google的缓解措施也受到了一定限制。
如今,Google很高兴分享这一Web API的最新更新,包括重新设计的Web模型加载系统。这一更新使Google能够运行更大的模型,例如拥有70亿参数的Gemma 1.1 7B模型。这个8.6GB的文件比Google之前在浏览器中运行的任何模型都大数倍,且其响应质量的提升同样显著——欢迎在MediaPipe Studio中亲自体验!
在Web上运行LLMs
MediaPipe框架本质上是跨平台的,因此大部分代码都是用C++编写的,可以为多个目标平台和架构进行编译。为了在浏览器中运行代码,Google将整个代码库(包括非Web特定部分及其依赖项)编译为WebAssembly,这是一种可以高效运行于所有主流浏览器中的特殊汇编代码。这种方式为Google带来了出色的性能和可扩展性,但也增加了一些额外的限制,因为浏览器在一个沙盒虚拟机中运行WebAssembly,就像模拟一个独立的物理计算机一样。
值得注意的是,虽然WebAssembly影响了C++代码和CPU内存限制,但它并不限制GPU功能。这是因为Google使用了专为浏览器原生设计的WebGPU API,能够比以往更直接地访问GPU及其计算能力。为实现最佳性能,Google的机器学习推理引擎会将模型权重上传并完全在GPU上运行模型操作。
克服内存限制
与此相对,在从硬盘或网络加载LLM时,原始数据必须通过多个层级才能到达GPU:
- 文件读取内存
- JavaScript内存
- WebAssembly内存
- WebGPU设备内存
Google使用基于浏览器的文件读取API将原始数据引入JavaScript,再传递到C++ WebAssembly内存,最后上传到WebGPU,在那里进行所有操作。每个层级都有内存限制,因此Google设计了相应的系统架构来适应这些限制。
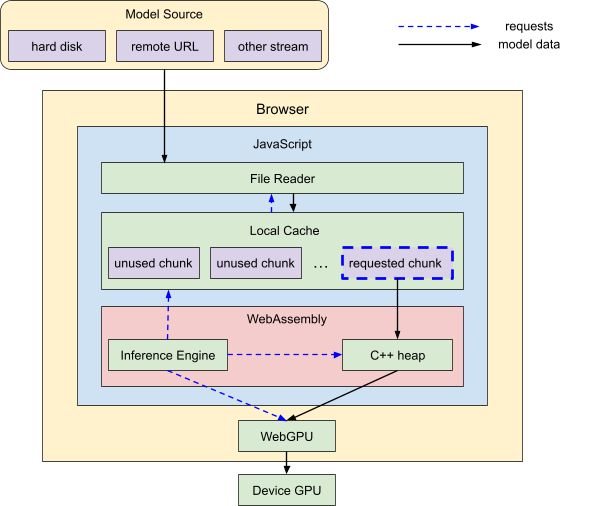
WebGPU设备内存
WebGPU设备的限制是硬件特定的,但幸运的是,大多数现代笔记本和台式机的GPU内存都足够Google使用。因此,Google专注于消除其他三项CPU内存限制,使GPU成为唯一的真正限制。
文件读取内存
Google早期的MediaPipe Web API在加载数据时大量使用JavaScript原语,如ArrayBuffer,但这些对象无法支持超过约2GB的大小。为了解决这个问题,Google设计了自定义的数据复制程序,依赖于更灵活的对象,如ReadableStreamDefaultReader。现在,Google在此基础上进一步开发,将巨大的文件分解为较小的块,并在需要时按需流式传输这些块。
WebAssembly内存
WebAssembly当前使用32位整数(范围为0到2^32-1)来索引其内存空间的地址,超过4.3GB的内存时,索引方案将溢出。为了应对这个挑战,Google利用了LLM的结构特性。LLM由许多部分组成,其中大部分二进制大小集中在变压器堆栈中。这个堆栈由一系列类似形状的模型层组成,依次运行。
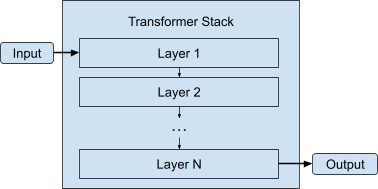
Gemma 1.1 7B模型有28层,这意味着如果Google能够将这些层逐一加载到WebAssembly内存中,内存使用可以提高28倍。因此,Google将同步加载管道更改为异步加载管道,由C++代码向JavaScript发出请求,并按需等待每个权重缓冲区。
实际结果甚至超出了预期:由于这些层本身包含许多较小的权重缓冲区,按需加载这些权重缓冲区使Google的WebAssembly内存峰值使用量降至不到1%的水平。
JavaScript内存
然而,这些升级也带来了一些弊端:Google现在在整个加载过程中进行一次性扩展扫描,无法按需跳转到文件的特定位置。这意味着加载顺序变得重要。解决方案是将模型权重按加载代码请求的顺序存储。然而,这种保证完全顺序的方式需要在模型格式中做出约定,或者让加载代码动态调整顺序。由于这些是更长期的解决方案,目前Google采用了备用方案,即创建一个临时本地缓存,在扫描数据时将未使用的数据保留,丢弃其余部分。
未来展望
在降低CPU内存使用方面,Google还可以通过减少模型大小来进一步优化,例如通过应用更激进的量化策略。Google希望很快能为Gemma 1.1 7B模型发布一个int4版本,在保持质量的同时,将模型大小减半。
此外,Google还在不断优化性能,添加令人期待的新功能,例如动态LoRA支持、即时微调和多模态支持。敬请期待更多更新,包括Gemma 2的发布!