
受生成建模实证成功的启发,研究团队发现,通过从非结构化和噪声数据中学习,超大规模神经网络能够提取出强大的数据表示。在本文中,他们探索了这种方法在消费健康数据领域的扩展潜力,特别是如何通过更高效的样本学习推动运动和活动识别等任务的实现。
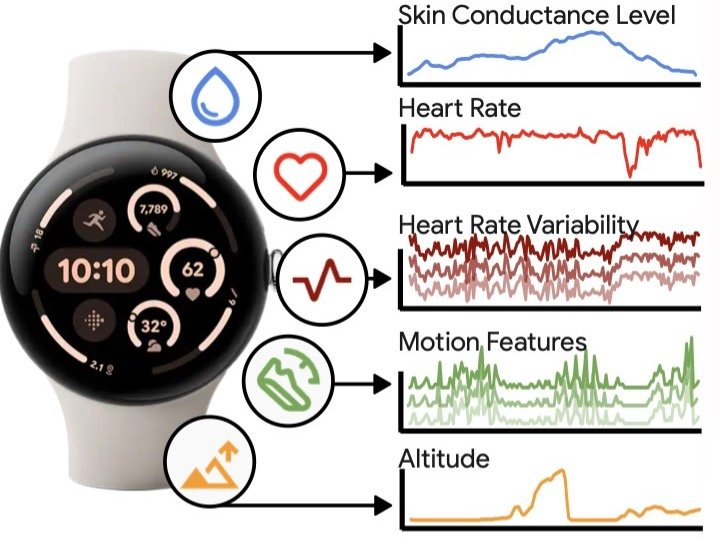
穿戴设备:从海量数据到有意义的洞察
如今,能够测量生理与行为信号的穿戴设备已成为日常生活的一部分。这些设备不仅能促进健康行为,还能用于疾病检测以及改善治疗方案的设计与实施。然而,这些设备生成的数据连续、纵向且多模态,其原始信号(如皮肤电活动或加速度计数据)往往难以解读。因此,各种算法应运而生,将这些原始数据转化为更有意义的表示形式。
传统上,这类算法依赖于监督学习模型(如分类模型),旨在检测特定事件或活动(例如识别用户是否正在跑步)。然而,这种方法存在三大限制:
- 标注数据有限且类别不均衡,导致大量潜在有价值的无标注数据未被利用。
- 模型专注于单一任务,缺乏通用性,难以在不同任务间迁移。
- 训练数据的异质性受限,通常只来自少量参与者(通常为几十到几百人)。
自监督学习(SSL)的突破
SSL通过通用的预训练任务(如拼图重排或图像补全)生成多用途的数据表示,无需依赖标签,能够利用更大比例的可用数据。这种方法为处理穿戴设备生成的大量无标注数据提供了新思路。
结合生成模型在理论与实践中的扩展规律,研究团队提出一个关键问题:扩展定律是否适用于穿戴设备传感器数据?与文本、视频或音频不同,传感器数据具有独特的特点。理解这种扩展规律的表现,不仅能优化模型设计,还能提升任务和数据集之间的泛化能力。

LSM:可扩展的穿戴设备基础模型
在研究中,团队分析了扩展定律是否适用于规模化的多模态传感器数据。他们使用目前最大规模的穿戴设备数据集,包含来自16.5万用户、超过4000万小时的去标识化多模态传感器数据。通过这一数据集,他们训练了一个基础模型,称为大传感器模型(LSM),并在数据、计算和模型参数等维度上展示了显著的性能提升,相较传统方法,性能最高提升了38%。
数据采样与模型训练
参与者佩戴Fitbit Sense 2或Google Pixel Watch 2设备,采集时间覆盖2023年1月至2024年7月。每位参与者提供自报告的性别、年龄、体重和居住州,数据均已去标识化。为了增加数据多样性,研究团队从每位参与者中随机抽取10个5小时窗口的数据。
训练模型时采用了一种“遮蔽”方法,即随机隐藏部分传感器数据,让模型学习如何重建这些缺失部分。这种方法帮助模型识别数据中的潜在模式,不仅适用于下游分类任务,还能实现数据补全(插值)和预测未来信号(外推)的能力。
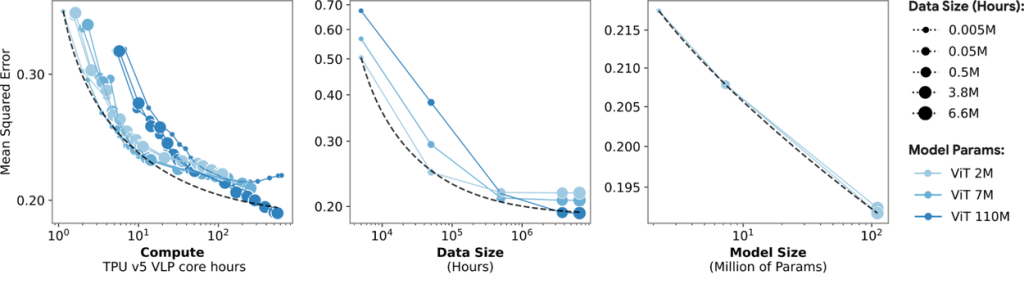
扩展定律验证与任务应用
研究团队进行了多维度扩展实验,重点分析了计算能力、数据量和模型参数规模对模型性能的影响。结果表明:
- 计算扩展:随着计算资源的增加,模型性能呈次线性增长,高计算资源条件下增益逐渐减弱,与语言模型和视觉模型的表现一致。
- 数据扩展:数据量显著影响模型性能。随着训练数据达到100万小时以上,大型模型(如ViT-110M)仍能保持较高增益,充分利用其潜力。
- 模型任务:在运动和活动分类任务中,LSM在少样本学习场景下表现出色,无论是仅有5或10个标注样本,还是随着标注样本增加,其性能均显著优于从零开始训练或有限监督的基线模型。
此外,研究发现,与增加参与者人数相比,增加每位参与者的数据时长对模型性能的影响更大。这可能是因为更丰富的个人活动样本能帮助模型捕获更复杂的模式。然而,为了实现模型的最大化泛化能力,同时扩展参与者数量和数据时长是理想选择。

未来方向
研究成果证明了大规模数据、模型和计算的扩展策略能够显著提升穿戴设备传感器模型的能力。未来,团队计划探索多样化数据集和定制化预训练技术,以进一步应对穿戴设备数据的独特挑战,为个人健康技术的发展贡献力量。