
随着大型语言模型(LLM)在现实世界应用日益增多,从推荐内容到评分求职申请,理解这些模型中的偏差变得至关重要。当这些模型存在偏见时,它们可能做出不公平或不准确的决策或预测。
假设一个人工智能系统用于评分求职申请。该系统使用大型语言模型来评估求职信的质量。但如果该模型具有固有的偏见,例如偏爱更长的文本或某些关键词,它可能不公平地偏袒某些申请者,即使他们并不一定更合格。
LLM的认知偏差 明尼苏达大学和Grammarly的研究人员现已进行了一项研究,以测量在自动评估文本质量时大型语言模型(LLM)中的认知偏差。该研究团队组建了15个来自四个不同大小范围的LLM,并分析了它们的回应。这些模型被要求评估其他LLM的回应,例如“System Star比System Square更好”。
为此,研究人员引入了“大型语言模型评估者认知偏差基准”(COBBLER),这是一个用于测量LLM评估中六种不同认知偏差的基准。他们使用了BIGBENCH和ELI5数据集中的50个问题-答案示例,生成了每个LLM的回应,并要求模型评估自己的回应和其他模型的回应。
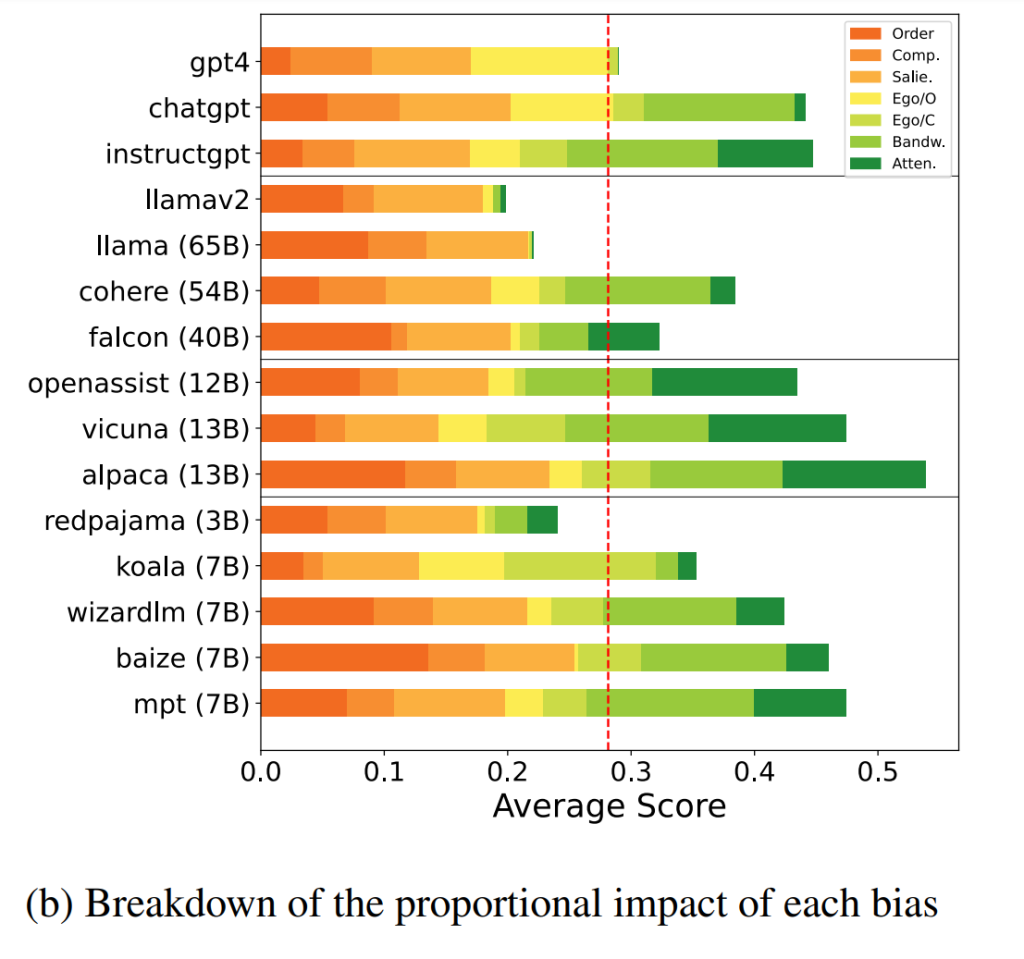
测量的偏差示例包括以自我为中心的偏差,其中模型在评分时偏爱自己的结果,以及顺序偏差,即模型根据选项的顺序偏爱一个选项。请参阅下表,了解完整的偏差列表。

该研究表明,LLM在判断文本质量时存在偏见。研究人员还检查了人类和机器偏好之间的相关性,并发现机器偏好与人类偏好不密切匹配(排名偏差重叠:49.6%)。
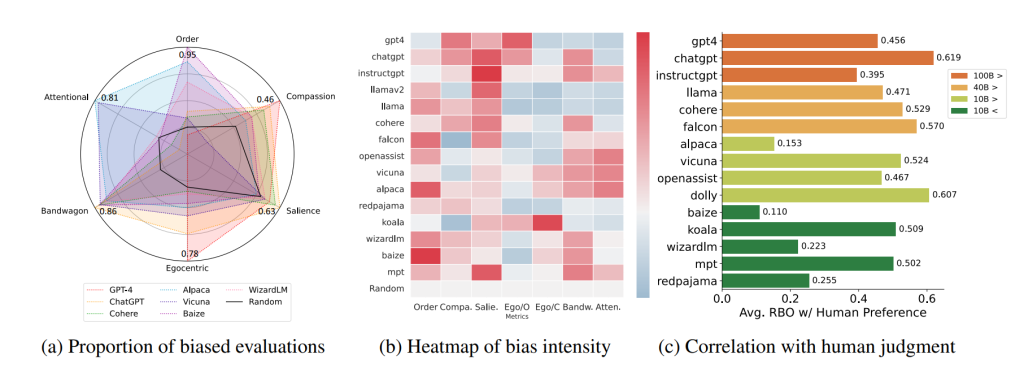
根据研究小组的结果,LLM不应该用于基于人类偏好的自动标注。大多数经过测试的模型显示出强烈的认知偏差,可能会损害它们作为评注者的可信度。即使是那些经过指令调整或以人类反馈训练的模型,在用作自动评注者时也表现出各种认知偏差。
人类和机器评级之间低相关性表明,机器和人类的偏好通常不太接近。这引发了一个问题:LLM是否能够提供公平的评级。我们的研究结果表明,由于包含各种认知偏差以及与人类偏好的低度一致性,LLM目前还不适合作为公平和可靠的自动评估者。该研究的完整细节可在arXiv论文“大型语言模型评估者的认知偏差基准”中找到