
在不断变化的人工智能领域,一种革命性的概念——联邦学习(Federated Learning,FL)引起了广泛关注。这种尖端技术允许在不同设备和位置上合作训练机器学习模型,同时确保个人数据远离窥探目光安全存储。这既利用了数据优化模型,又兼顾了隐私保护,可谓是两全其美。
尽管联邦学习令人兴奋,但在这一领域进行研究对数据科学家和机器学习工程师来说是一个真正的挑战。模拟现实的、大规模的FL场景一直是一个持续的难题,现有工具在速度和可扩展性上难以满足现代研究的需求。

本文介绍了一个名为pfl-research的突破性Python框架,旨在为您的私有联邦学习(PFL)研究工作提供强大动力。这个框架快速、模块化且用户友好,使研究人员能够迅速迭代和探索新思想,而不会被计算限制所困扰。
pfl-research的一个突出特点是其多功能性。它就像一个会说TensorFlow、PyTorch甚至是传统非神经网络模型多种语言的研究助理。而且,pfl-research与最新的隐私算法兼容良好,确保在你推动可能性的边界时,你的数据安全如虫。
但真正让pfl-research与众不同的是其积木式的方法。它就像是研究人员的高科技乐高套装,包含了数据集、模型、算法、聚合器、后端、后处理器等模块化组件,你可以自由组合,创建出符合你特定需求的仿真。无论是想在大型图像数据集上测试新的联邦平均算法,还是需要在分布式文本模型上试验不同的隐私保护技术,pfl-research都能满足你的需求。
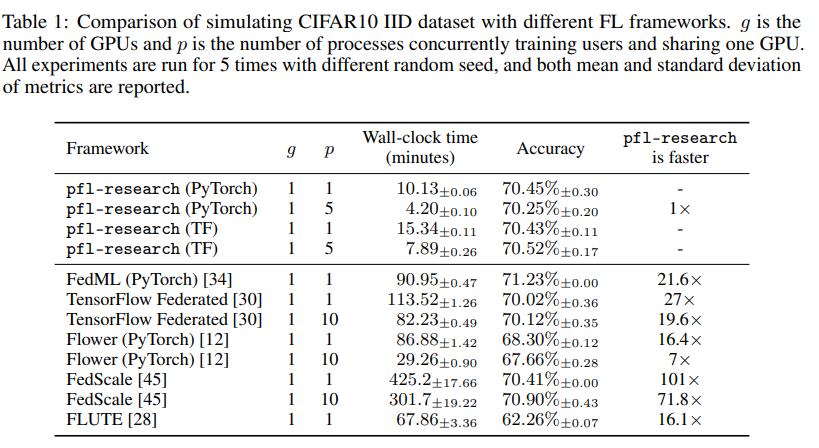
现在,事情变得更加激动人心。在与其他FL模拟器的测试中,pfl-research的仿真速度最高可达竞争对手的72倍。有了pfl-research,你可以在庞大的数据集上运行实验,而不会流一滴汗或牺牲研究质量。
但pfl-research团队并没有因此自满。他们有宏伟的计划继续改进这一工具,比如不断添加对新算法、数据集和跨库仿真(想象一下跨多个组织或机构的联邦学习)的支持。他们还在探索尖端的仿真架构,以推动可扩展性和多功能性的界限,确保pfl-research在联邦学习领域持续发展中保持领先。
想象一下pfl-research为你的研究开启的可能性。你可能会是第一个破解隐私保护自然语言处理代码的人,或者开发出针对个性化健康应用的开创性联邦学习方法。
在不断进化的人工智能研究世界中,联邦学习是一场游戏规则的改变者,而pfl-research是你的终极助手。它快速、灵活、用户友好,是任何希望在这一激动人心的领域中开辟新天地的研究者的梦想组合。