
自从Qwen2发布后的三个月内,众多开发者基于Qwen2语言模型构建了新模型,并提供了宝贵的反馈。在此期间,Qwen团队专注于打造更智能、更具知识性的语言模型。今天,全新Qwen系列的最新成员——Qwen2.5,隆重登场!官方宣布了有史以来规模最大的开源发布之一!让我们开始狂欢吧!
https://github.com/QwenLM/Qwen2.5
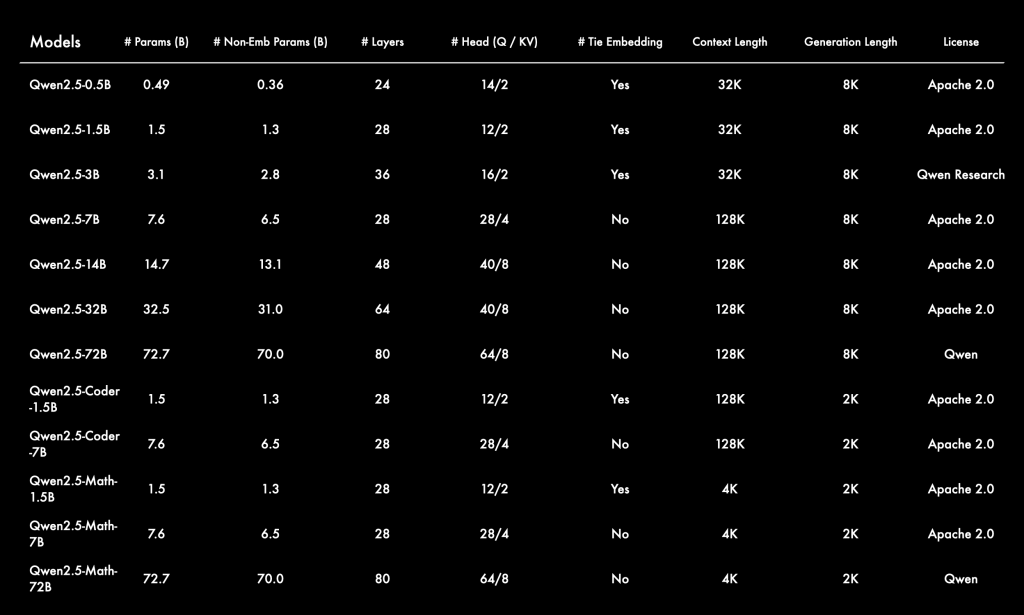
此次发布的重磅内容包括通用大模型Qwen2.5,以及专注于编程的Qwen2.5-Coder和数学的Qwen2.5-Math。所有开源权重模型均为稠密、仅解码语言模型,涵盖多种尺寸,如下所示:
- Qwen2.5:0.5B、1.5B、3B、7B、14B、32B和72B
- Qwen2.5-Coder:1.5B、7B和32B即将上线
- Qwen2.5-Math:1.5B、7B和72B
除了3B和72B版本,所有模型都采用Apache 2.0许可协议,相关文件可在Hugging Face的对应库中找到。此外,用户还可以通过Model Studio体验Qwen-Plus和Qwen-Turbo等旗舰语言模型的API服务。Qwen团队还开源了Qwen2-VL-72B,与上月发布的版本相比进行了性能优化。
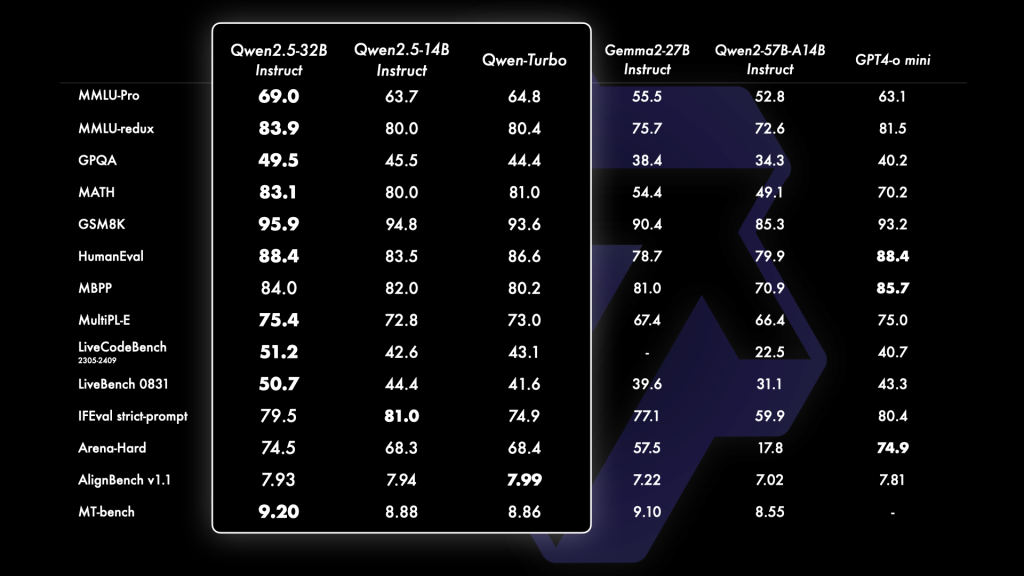
Qwen2.5的所有语言模型都经过最新大规模数据集的预训练,数据量高达18万亿tokens。与Qwen2相比,Qwen2.5在知识储备(MMLU: 85+)、编程能力(HumanEval 85+)和数学能力(MATH 80+)方面有显著提升。此外,模型在指令遵循、长文本生成(超过8K tokens)、结构化数据理解(例如表格)、结构化输出生成(特别是JSON格式)等方面也有了巨大进步。Qwen2.5还支持多达128K tokens的处理能力,支持生成长达8K tokens的文本,并保留了对包括中文、英语、法语等29种语言的多语种支持。
Qwen2.5-Coder和Qwen2.5-Math这两款专家模型相比其前辈也有了显著的增强。Qwen2.5-Coder经过了5.5万亿代码相关数据的训练,即使是较小的编程专用模型,也在代码评测中展现出与更大语言模型竞争的能力。Qwen2.5-Math支持中文和英语,并引入了连锁思维(CoT)、程序思维(PoT)和工具整合推理(TIR)等多种推理方式。
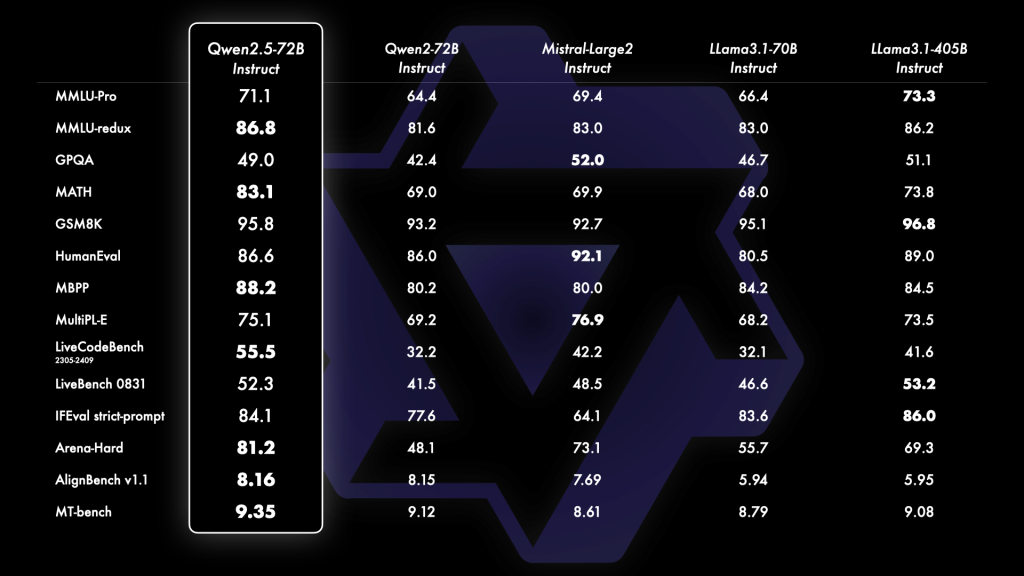
Qwen2.5系列在不同的尺寸模型中展现了强大的性能,尤其是Qwen2.5-72B,它在多个指令调整基准上超越了同类的开源大模型如Llama-3.1-70B和Mistral-Large-V2。而且,即便是Qwen2.5-3B这样的较小模型,也在知识密度和性能方面大放异彩,展示了其高效的能力。
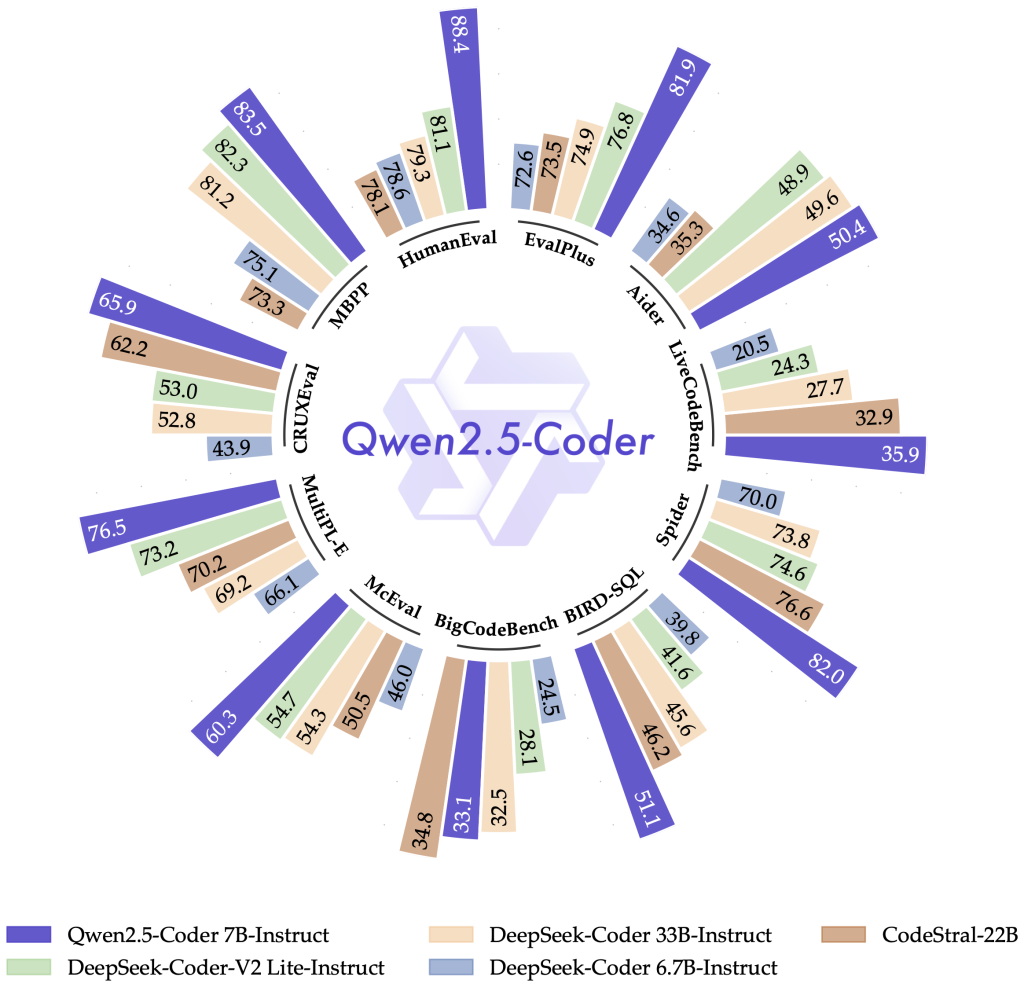
此外,Qwen团队还在后期训练方法上做了四大更新,包括支持生成长达8K tokens的文本、结构化数据理解、生成结构化输出(如JSON格式),以及对多种系统提示的适应性提升,使得角色扮演和条件设置更加灵活。对编程领域的用户来说,Qwen2.5-Coder展现了卓越的性能,虽然模型参数较小,但在多种编程语言和任务中表现优异,堪称个人编程助手的最佳选择。
至于数学领域,Qwen2.5-Math相较于Qwen2-Math预训练了更大规模的数学数据,并加强了推理能力,甚至其1.5B的小型号模型也能在数学任务中与大语言模型竞争。
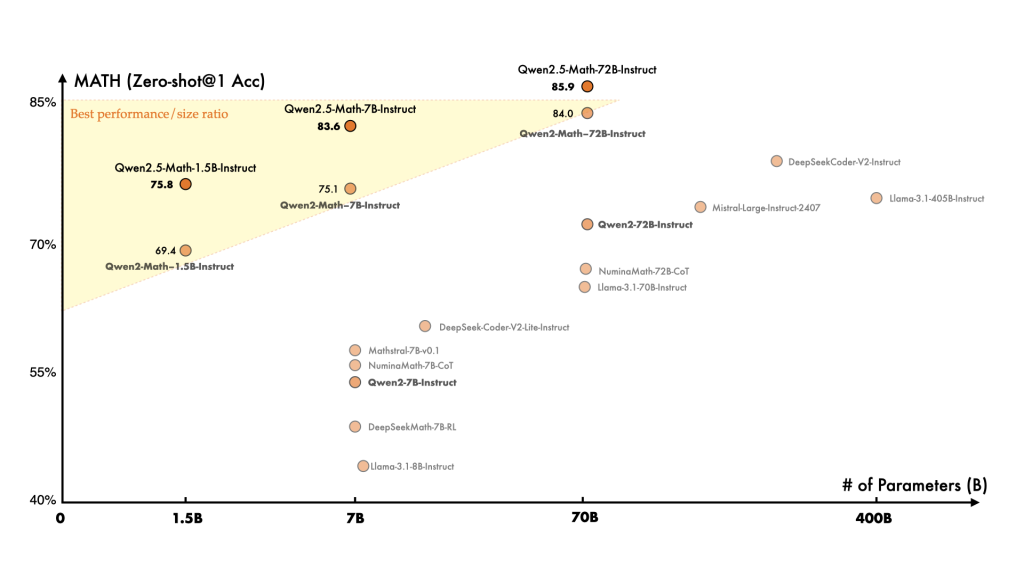
总之,Qwen2.5系列在各个领域都取得了突破性进展,用户可以通过Hugging Face、vllm等多种途径便捷使用这些模型。Qwen2.5还支持工具调用功能,让用户在编程、数学等任务中如虎添翼。通过这些强大的模型,Qwen团队期待看到更多惊人的应用和创新。
准备好开启无限可能的世界吧!