
大型语言模型(LLMs)已成为自然语言处理领域的基础,尤其是在需要理解复杂文本数据的应用中。然而,由于模型体积庞大,计算资源需求巨大,因此在延迟、内存占用和功耗方面面临着挑战。为使LLMs更适合规模化应用,研究人员正在积极开发降低计算成本的技术,同时保持模型的精度和实用性。这项努力主要集中在改进模型架构上,通过减少数据表示所需的比特数,使高性能语言模型能够在各种环境中大规模部署成为可能。
LLMs的资源密集型特性是其长期存在的问题,尤其是在推理阶段,要求大量的计算能力和内存。尽管模型优化方面已有进展,但计算成本仍是许多应用的门槛。其开销主要源于庞大的参数量和处理输入与生成输出所需的复杂操作。此外,随着模型复杂性的增加,量化误差的风险也随之上升,进而可能影响精度和可靠性。为应对这些效率挑战,研究领域正着力于降低权重和激活值的比特宽度,以减少资源消耗。
为应对效率问题,已经提出了多种方法,其中激活稀疏化和量化成为了重要手段。激活稀疏化通过选择性地停用低幅值的激活项来减少计算负荷,特别适用于长尾分布的激活数据,其中许多不重要的数值可以被忽略而不影响性能。而激活量化则是通过降低激活值的比特宽度来减少每一步计算所需的数据传输和处理资源。然而,这些方法在遇到数据中的大幅值异常值时往往会受到限制,因为这些异常值在低比特表示下更难以精确处理,可能会引发量化误差,影响模型的准确性,并阻碍LLMs在资源受限环境中的部署。
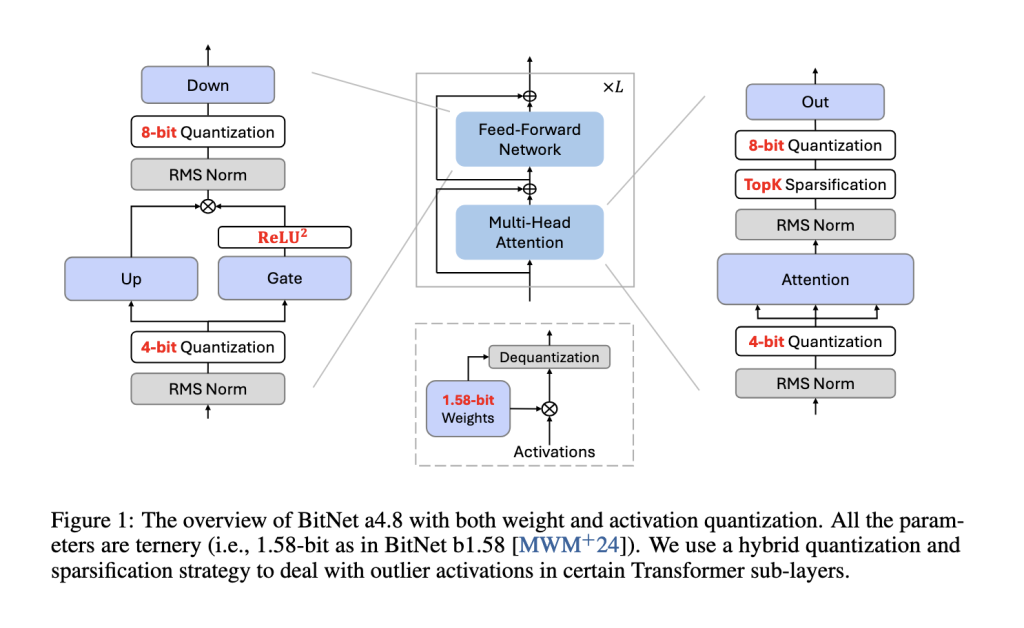
对此,微软研究院和中国科学院大学的研究团队提出了一种新方案,名为BitNet a4.8。该模型采用混合量化与稀疏化的方法,实现了4比特激活和1比特权重。BitNet a4.8通过在中间状态中结合低比特激活和稀疏化,成功降低了计算需求,同时保持高准确性。通过选择性量化,该模型提供了一种高效的解决方案,有望将LLMs大规模部署在多种资源受限环境中。
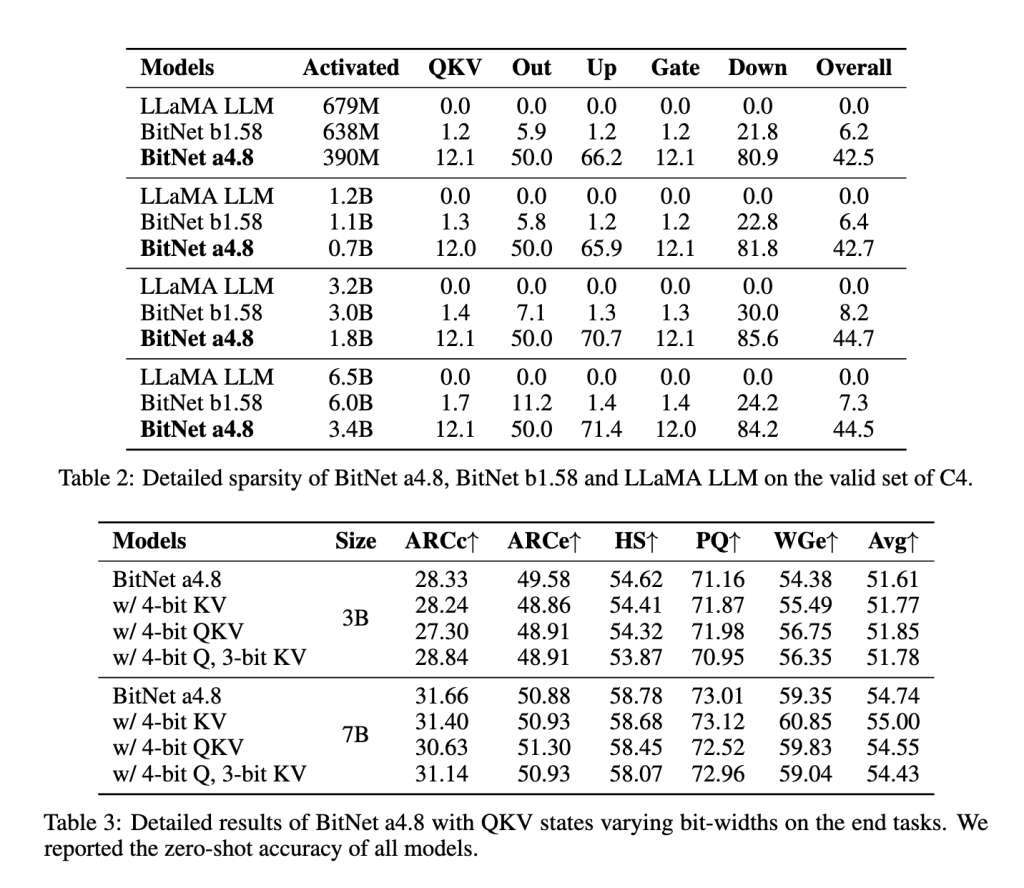
BitNet a4.8的核心方法是一种两阶段的量化和稀疏化流程,专门用于降低异常值维度的量化误差。首先,模型在8比特激活下进行训练,逐步转向4比特激活,使其在保持精度的同时逐步适应低精度。这种两阶段训练方法使BitNet a4.8可以在量化误差较小的层中使用4比特激活,而在对精度要求较高的中间状态层则保留8比特稀疏化。通过针对特定层的量化敏感度调整比特宽度,BitNet a4.8在计算效率和模型性能之间达到了最佳平衡。此外,该模型仅激活55%的参数,并采用3比特的KV缓存,进一步提升了内存效率和推理速度。
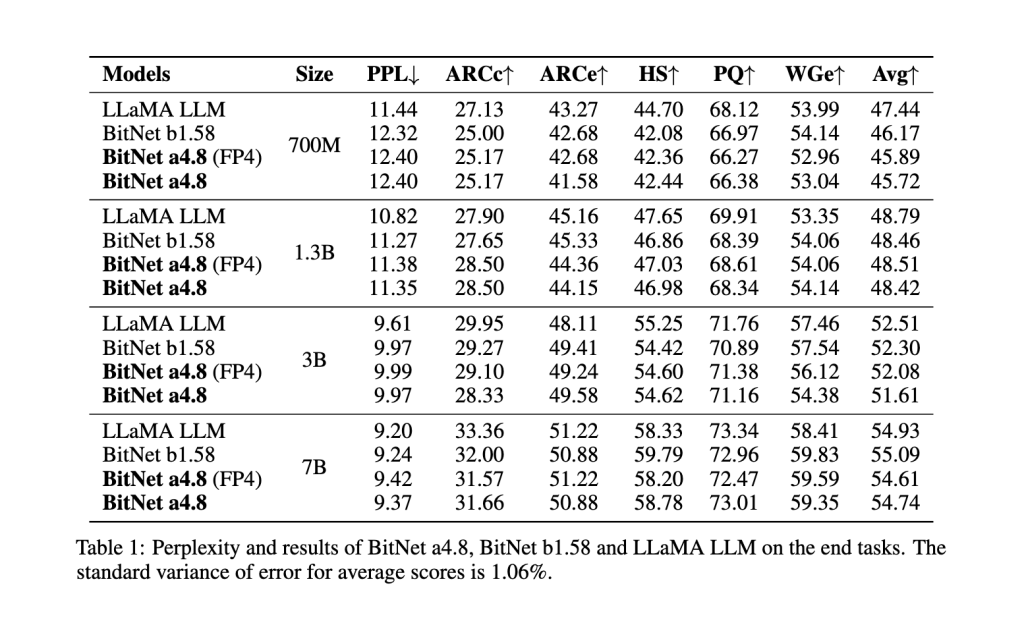
在多项基准测试中,BitNet a4.8的性能超越了其前身BitNet b1.58以及其他模型如FP16 LLaMA LLM。在与BitNet b1.58的直接对比中,BitNet a4.8在保持相似精度的情况下提高了计算效率。例如,在7亿参数配置下,BitNet a4.8达到了9.37的困惑度分数,接近LLaMA LLM的水平,并在下游语言任务中表现出与全精度模型相差无几的平均准确率。其架构在最大配置测试中实现了高达44.5%的稀疏度,7亿参数版本中有3.4亿激活参数,显著减少了计算负荷。此外,3比特KV缓存加速了处理速度,使BitNet a4.8成为在不牺牲性能的前提下实现高效部署的有力候选。
综上所述,BitNet a4.8在应对LLMs计算挑战方面提供了颇具前景的解决方案,通过其混合量化和稀疏化的方法有效地平衡了效率与精度。这一方法增强了模型的可扩展性,为LLMs在资源受限环境中的部署开辟了新的途径。BitNet a4.8通过优化比特宽度和减少激活参数,成为了大规模语言模型部署的可行选项。