
在网络数据集数量急剧增长的今天,数据集间复杂的关系越来越重要,尤其对于数据研究人员和使用数据集的从业者。Google的研究工程师Kate Lin和研究科学家Tarfah Alrashed在《Relationships are Complicated! An Analysis of Relationships Between Datasets on the Web》中提出了一套方法,通过自动化识别网络数据集关系,以帮助用户在数据集发现过程中更高效地找到、评价和引用数据集。本文基于schema.org标记的网络数据集大规模语料库进行了这些方法的性能比较。
数据集关系的定义
研究团队定义了用户在数据集发现和共享过程中可能进行的四个关键任务:
- 寻找数据集:网络数据集的数量和多样性让用户在寻找数据时面临巨大挑战。
- 评估数据集可信度:数据集通常缺乏同行评审,用户必须通过数据集属性和元数据来评估其可信度。
- 引用和参考数据集:数据集引用支持数据的标准化管理,需要持久标识符和准确的出处描述。
- 数据集管理:数据集管理包括从多个来源收集和维护数据集,以确保用户可以长期访问高质量的数据。
基于这些任务,研究将数据集关系分为两大类:源起关系和非源起关系。源起关系包括相同数据集在不同平台上的“副本”、随时间更新的“版本”、特定数据集的“子集”、多数据集组合的“派生”关系等。而非源起关系则基于数据内容或用途的关联性,比如主题相似或可整合的数据集。
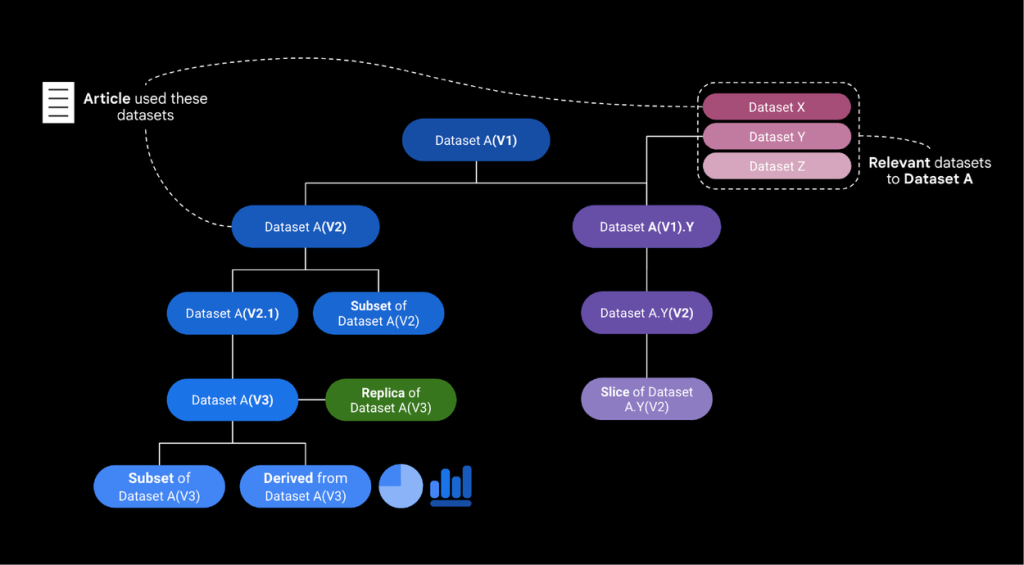
方法开发与分析
研究团队开发了四种识别方法,并对这些方法在不同关系类别上的性能进行了对比:
- schema.org标注提取:直接从schema.org标记中提取关系,但由于schema.org的标注往往不完整,尤其在数据集关系标记方面存在明显不足。
- 启发式方法:基于各类关系类型的特征,定制了一组高效的启发式规则。
- 传统机器学习(GBDT分类器):使用基于梯度提升决策树的模型,以提高多类别关系的识别准确性。
- 生成式AI方法(T5模型):基于生成式大语言模型的关系分类器,利用T5模型识别数据集关系。
实验结果
团队从网络抓取包含schema.org元数据的网页,生成了一个包含270万个数据集元数据条目的语料库。通过对2,178对数据集手动标注生成了用于训练和测试的“真值”数据。实验表明,GBDT和T5模型在识别数据集关系方面表现最佳,其中GBDT在各类别关系的F1评分上领先,T5模型在派生关系识别中表现尤为优异。然而,schema.org标注方法的整体准确率较低,仅为0.33,而启发式方法为0.65。GBDT和T5模型的总体准确率分别达到了0.90和0.89。

结论与未来展望
实验表明,当前schema.org元数据不足以完整捕获数据集间的关系,特别是在检测版本、子集和派生关系时存在较大不足。研究人员建议改进schema.org的元数据标准,使其更好地适应数据集发现和使用需求,同时推广最佳实践以鼓励数据集作者标注更详细的元数据。
未来,研究团队计划进一步探索非源起关系,优化数据集的检索和使用体验,帮助用户快速找到适合其需求的数据集,并推进数据共享标准的发展。