
大型语言模型正在推动人工智能技术的快速发展,例如GPT-4和BERT等模型,对计算资源的需求极为庞大。选择合适的图形处理器(GPU)是优化性能和控制成本的关键,不同用户在选择时需要根据实际需求在性能与预算之间找到平衡。以下是针对不同应用场景的图形处理器推荐,以及挑选时需要重点关注的关键参数解析。
关键参数解析
- CUDA核心数:CUDA核心是图形处理器的主要计算单元,核心数量越多,通常意味着更强的并行计算能力。
- Tensor核心:Tensor核心专为深度学习任务设计,用于高效执行矩阵运算,是人工智能推理性能的重要保障。
- 显存容量(视频内存):显存的大小决定了图形处理器能够处理的模型和数据规模。显存越大,越适合处理复杂的大型模型任务。
- 核心频率:核心频率代表图形处理器的运行速度,频率越高通常带来更好的性能表现。
- 内存带宽:内存带宽是显存数据读写的速率,对处理大规模推理任务具有显著影响。
- 功耗:功耗越高通常意味着更强的性能,但同时也会带来更高的冷却需求和运行成本。
- 价格:对于预算有限的团队或个人用户来说,找到性能与成本的合理平衡非常重要。
高性能图形处理器推荐
NVIDIA H200
- 适用场景:企业级人工智能部署及大规模语言模型推理任务。
- 性能亮点:配备18432个CUDA核心、96GB的HBM3显存,以及高达4000GB每秒的内存带宽,是目前性能最强的选项之一。
NVIDIA H100
- 适用场景:企业和研究机构的大型语言模型推理项目。
- 性能亮点:拥有16896个CUDA核心和80GB的HBM3显存,在性能和功耗之间达成了理想平衡,适合高负载人工智能工作负载。
NVIDIA A100
- 适用场景:追求高性价比的中型团队或研究机构。
- 性能亮点:提供40GB或80GB的HBM2e显存,以及1555GB每秒的内存带宽,是处理复杂人工智能模型任务的可靠选择。
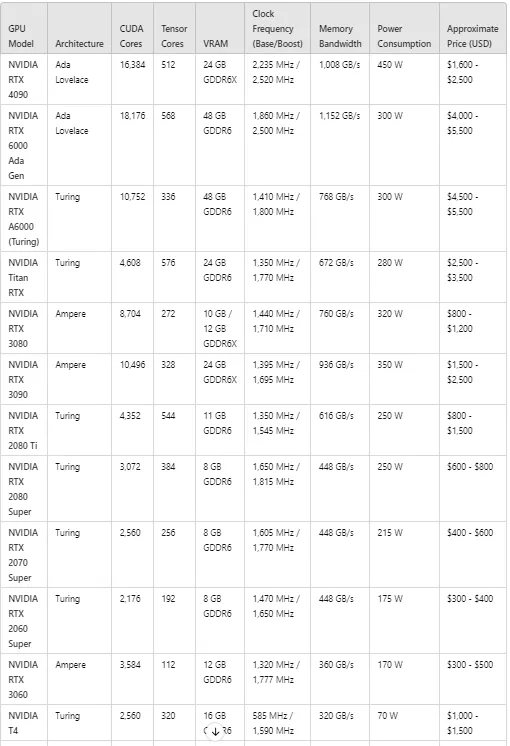
NVIDIA RTX 6000 Ada Generation
- 适用场景:中小型企业的专业人工智能推理需求。
- 性能亮点:配备48GB的GDDR6显存和18176个CUDA核心,性能和价格之间达到了良好的平衡。
NVIDIA L40
- 适用场景:中型企业的高效人工智能推理任务。
- 性能亮点:配备9728个Tensor核心和48GB的GDDR6显存,功耗低于其他高端型号,但性能依然非常强劲。
预算友好型图形处理器推荐
NVIDIA RTX 4090
- 适用场景:个人开发者或小型团队的高端人工智能推理需求。
- 性能亮点:配备24GB的GDDR6X显存和1008GB每秒的内存带宽,以较低的价格提供极高的性能,是预算有限用户的首选。
NVIDIA RTX 6000 Ada Generation
- 适用场景:需要高显存和高数据吞吐能力的专业人工智能任务。
- 性能亮点:提供48GB的显存和1152GB每秒的内存带宽,能够轻松应对大规模数据处理任务。
NVIDIA Titan RTX
- 适用场景:专业人工智能开发者的高性能需求。
- 性能亮点:配备24GB的GDDR6显存和672GB每秒的内存带宽,尽管架构稍显落后,但依然是可靠的选择。
NVIDIA RTX 3080 和 NVIDIA RTX 3090
- 适用场景:人工智能初学者或对高性能需求的用户。
- 性能亮点:特别是RTX 3090,提供24GB的GDDR6X显存,性能与价格兼具,适合需要显存资源的复杂任务。
NVIDIA T4
- 适用场景:云端推理和边缘计算中的轻量级任务。
- 性能亮点:配备16GB的GDDR6显存,功耗较低,是预算有限用户的不错选择,特别适合小型人工智能应用。
总结
- 对于企业级人工智能部署,NVIDIA H200和H100以顶尖的性能满足大规模语言模型推理和其他高负载任务需求。
- 对于中型团队和研究机构,NVIDIA A100和RTX 6000 Ada Generation在性能和成本之间找到了良好平衡,是高性价比的选择。
- 对于个人开发者或小型团队,NVIDIA RTX 4090和RTX 3090提供了强大的性能,同时价格更为亲民。
- 对于预算敏感且任务轻量化的用户,NVIDIA T4以较低的功耗和合理的性能满足了云端推理和边缘场景需求。
在选择图形处理器时,根据项目规模、模型复杂度以及预算限制,找到最适合的解决方案是实现高效人工智能任务的关键。