
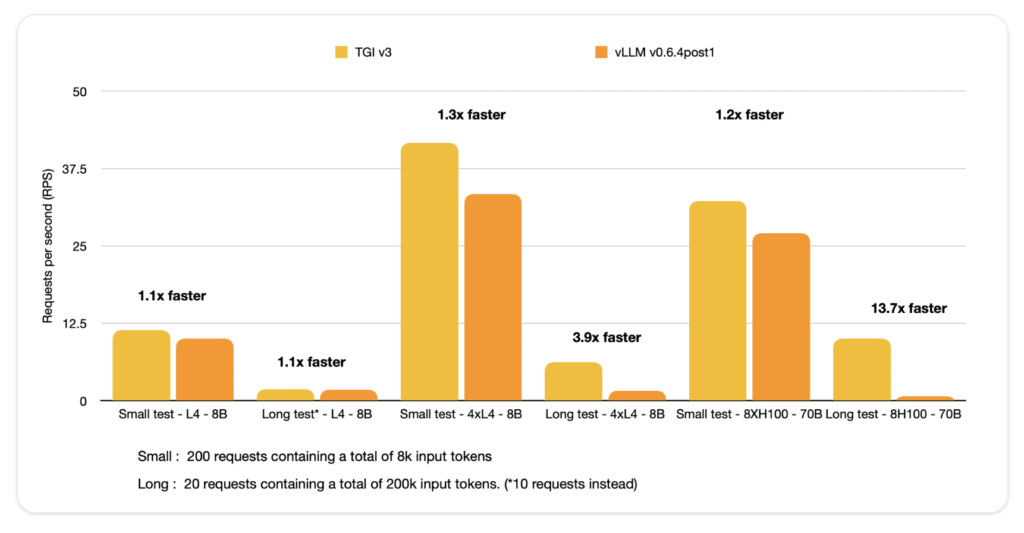
Hugging Face推出了全新文本生成推理引擎 (TGI) v3.0,这一版本的性能堪称惊艳:在处理长提示词时,其速度比vLLM快了13倍!这一突破为自然语言处理(NLP)领域的长文本生成带来了划时代的效率提升,同时通过零配置部署让开发者使用起来更加便捷。用户仅需输入一个Hugging Face模型ID,即可享受强大的性能改进。
重大升级亮点:
TGI v3.0在多个核心指标上实现了质的飞跃。首先,它的单GPU token处理能力提升了三倍,同时显著减少了内存占用。例如,使用单个NVIDIA L4 GPU(24GB),运行Llama 3.1-8B模型时可以处理多达30,000个token,相比vLLM的同类设置,容量直接翻了三倍。此外,优化后的数据结构进一步加速了提示词上下文的检索,大幅缩短了长对话场景中的响应时间。
技术亮点
- 内存优化和动态管理
TGI v3.0通过降低内存开销,提高了处理长提示词的能力。对于硬件资源有限的开发者,这一特性尤其重要。单NVIDIA L4 GPU可处理的token数量是vLLM的三倍,大幅降低了扩展成本,成为开发者的高性价比选择。 - 高效的提示词优化机制
系统能够保留最初的对话上下文,从而在后续查询中几乎瞬间响应。通过优化后的查找机制,其上下文检索延迟仅为5微秒,彻底解决了许多对话式AI系统中常见的延迟问题。 - 零配置部署
TGI v3.0通过自动化配置,为用户提供了即插即用的体验。系统根据硬件和模型的实际情况自动调整至最佳设置,省去了手动调整的繁琐步骤。尽管高级用户仍可以使用特定配置标志进行微调,但大部分情况下,无需干预即可实现最佳性能。
性能测试与应用场景
在实际测试中,TGI v3.0展现出强大的能力:
- 超长提示词处理
面对超过20万token的提示词,TGI仅需2秒即可生成响应,而vLLM则需要27.5秒。这种13倍的性能提升,极大拓宽了长文本生成的应用范围。 - 内存优化
尤其是在生成长文本或处理复杂对话历史的场景下,这种内存优化显得尤为重要。即便是在显存受限的环境中,TGI依然能够高效运行而不超出内存上限。
行业意义
Hugging Face的这一技术突破,不仅提升了长文本生成的效率,还显著降低了NLP应用的开发门槛。其零配置模式为更多开发者打开了高性能NLP的大门,即便没有专业的优化经验,也能轻松部署复杂的AI应用。
结语
TGI v3.0无疑为文本生成技术树立了新的标杆。凭借在token处理、内存管理等方面的突破性创新,开发者现在可以以更少的硬件资源实现更快、更大规模的AI应用。随着NLP应用需求的不断增长,像TGI这样的工具将在应对规模和复杂性挑战中扮演关键角色。Hugging Face的这一发布,不仅展示了卓越的工程创新,还表明现代AI系统对高效工具的迫切需求正推动整个行业向前发展。