
中国研究人员终于揭开了 AI 在复杂推理任务中“掉链子”的秘密——这些模型往往过早放弃有潜力的解决方案,导致计算资源浪费,答案准确率也随之下降。

来自腾讯 AI Lab、苏州大学和上海交通大学的研究团队发现,像 OpenAI 的 o1 这样的推理模型在解题时总是不断切换策略,甚至频繁重启思路,比如爱用“换个角度来看……”这样的开头。随着问题变得更难,这种行为愈发明显,计算量也随之飙升,但结果却未必更准。
举个例子,QwQ-32B 模型在一个任务中尝试了 25 种推理路径,而 QwQ-32B-Preview 也在同一任务中不断变换思路,最终浪费了大量算力。研究发现,70% 的错误答案其实包含了正确的推理线索,但模型没有坚持下去。当 AI 给出错误答案时,它平均会多消耗 225% 的计算资源,并且策略变更频率比正确答案高出 418%!
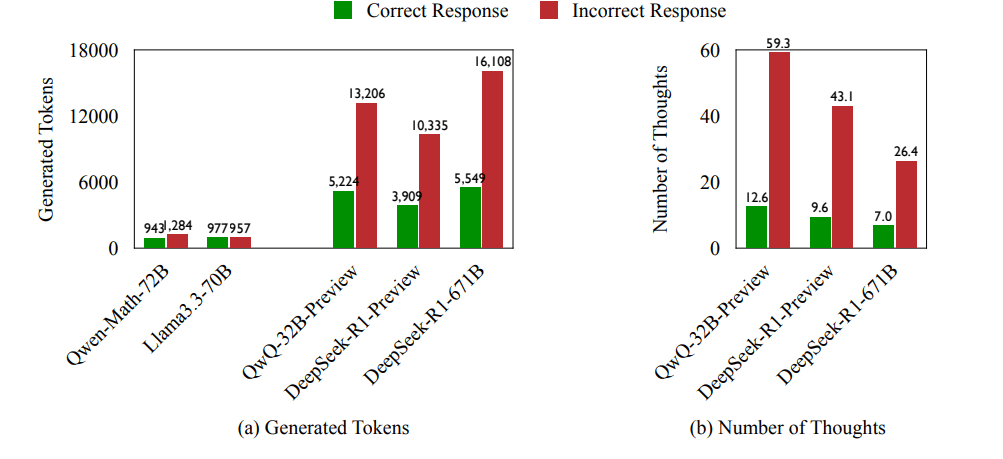
为了深入研究这一问题,团队专门设计了一项衡量模型计算效率的新指标,分析它们在得出错误答案时,有多少计算资源真正贡献在有效推理上,又有多少被无意义的策略切换浪费掉。
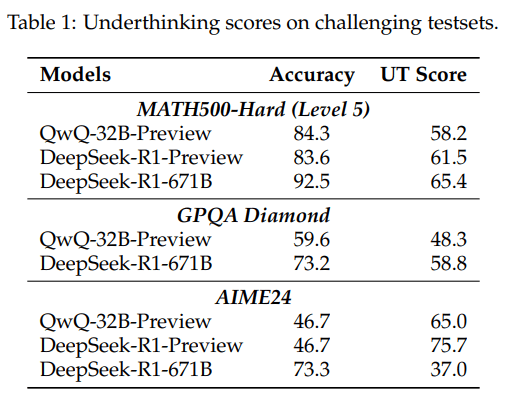
研究人员用三类高难度问题测试了 AI 的推理能力:数学竞赛题、大学物理题和化学问题,目标是评估 QwQ-32B-Preview、Deepseek-R1-671B 等模型如何处理复杂推理。结果显示,o1 这类大模型在面临难题时容易陷入“推理崩溃”,计算资源被不断尝试新方法消耗殆尽。然而,正确率更高的模型并不一定更高效,它们可能只是更擅长找到最终答案,而非更聪明地利用计算资源。
如何让 AI“坚持己见”?
为了解决“思维不坚定”问题,研究团队提出了一种新的解码策略——“思维切换惩罚”(TIP)。它通过调整模型的概率分布,降低某些表示策略变化的词语(比如“或者”)的权重,从而让 AI 在跳到新思路前,更深入地探索当前路径。
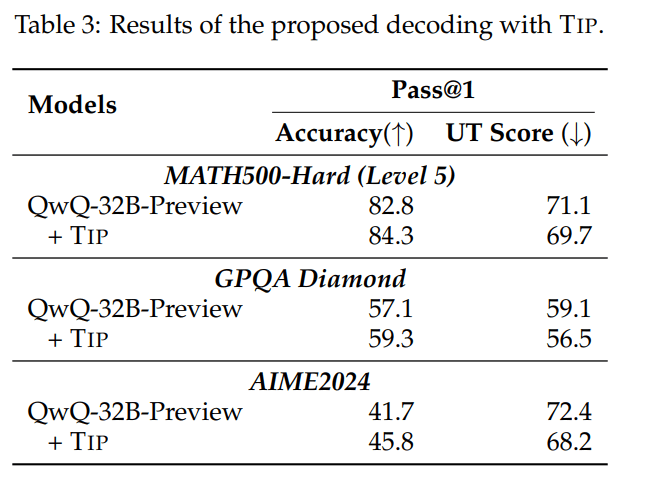
结果表明,TIP 确实让 AI 更加“坚定立场”:QwQ-32B-Preview 在数学竞赛 MATH500-Hard 任务中的正确率从 82.8% 提高到了 84.3%,并且推理过程更加稳定。这一改进同样适用于 GPQA Diamond、AIME2024 等高难度测试集。
研究人员表示,这项研究揭示了一个关键点——提升 AI 的推理能力并不只是堆砌更多算力,而是要教会模型什么时候应该坚持,什么时候才该换思路。未来,他们计划进一步优化 AI 的问题解决方式,让它们自主判断“该坚持还是该变通”,从而真正实现更高效、更聪明的推理过程。