
近年来,视觉语言模型(Vision-Language Models,简称VLM)在图像、视频与文本模态的融合方面取得了显著进展。然而,多数VLM仍存在一个关键瓶颈:难以高效处理长上下文的多模态数据,如高分辨率图像或长时间视频序列。现有模型通常面向短上下文任务进行优化,当输入变长时,容易出现性能下降、内存使用低效或语义细节丢失等问题。要解决这些挑战,不仅需要架构层面的灵活性,也需在数据采样、训练策略和评估体系上采取创新方法。
Eagle 2.5:面向长上下文学习的通用模型框架
NVIDIA最新推出的Eagle 2.5是一系列面向长上下文多模态理解的视觉语言模型。与单纯扩大输入token数量的方式不同,Eagle 2.5在输入长度增加时能够持续提升性能,尤其适用于图像与视频理解等任务,其目标在于捕捉长篇内容中的丰富语义。
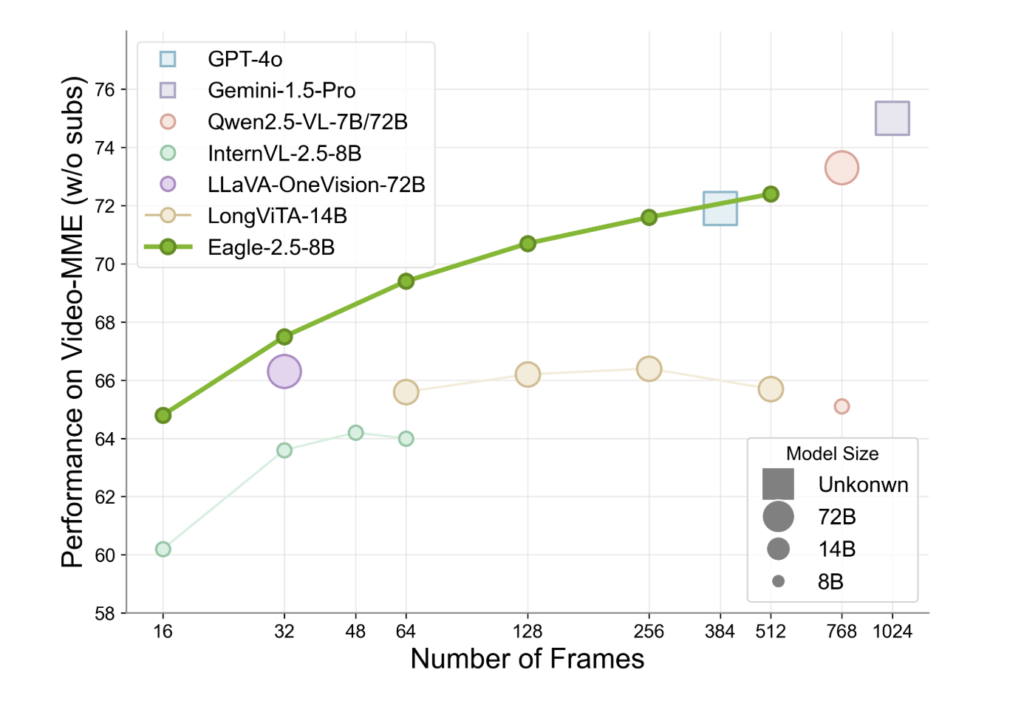
Eagle 2.5以相对紧凑的8B参数体量,在多个权威评测中表现出色。在Video-MME(512帧输入)任务上,其得分达72.4%,已接近或持平于参数量大十倍以上的模型,如Qwen2.5-VL-72B与InternVL2.5-78B。值得一提的是,这一成绩在未使用任何任务特定压缩模块的前提下实现,体现出其通用模型的架构理念。
训练策略:上下文感知优化
Eagle 2.5的高效表现得益于两大互补训练策略:信息优先采样(Information-First Sampling)与渐进式后训练(Progressive Post-Training)。
- **信息优先采样(Information-First Sampling)**引入图像区域保持(Image Area Preservation, IAP)机制,通过拼图式切割保持超过60%的原图面积,同时减少纵横比畸变;自动退化采样(Automatic Degradation Sampling, ADS)则根据上下文长度动态平衡视觉与文本输入,确保文本序列完整,并智能调整图像细节层级。
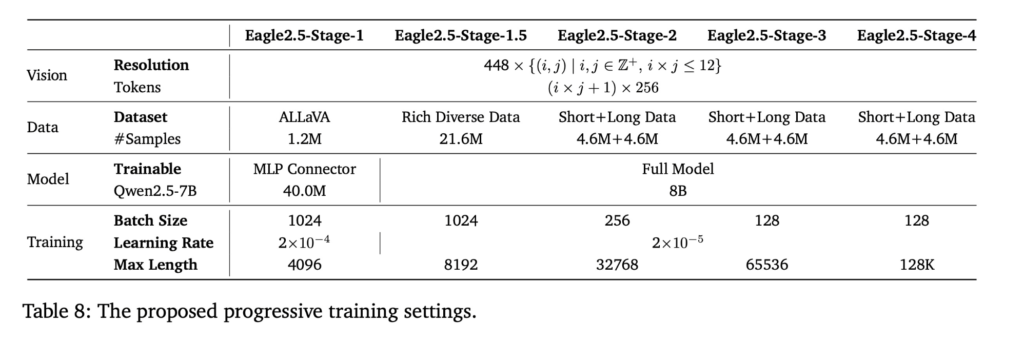
- **渐进式后训练(Progressive Post-Training)**通过分阶段扩展上下文窗口,从32K逐步扩展至64K、128K token,使模型在不同长度下均具备稳定性能,避免过拟合于单一输入范围。
该训练方案基于SigLIP架构实现视觉编码,辅以多层感知器(MLP)投影层以对齐语言模型主干,同时放弃了领域专属压缩组件,以保留模型在多任务间的通用适应性。
Eagle-Video-110K:支持长视频理解的结构化数据集
Eagle 2.5的重要组成部分是其训练数据流程,其中不仅整合开源资源,还引入专为长视频理解设计的定制数据集——Eagle-Video-110K。该数据集采用双重注释策略构建:
- 自上而下策略引入章节级的结构信息,由人工注释章节元数据,并结合GPT-4生成的密集字幕与问答对;
- 自下而上策略则通过GPT-4o对短片段自动生成问答对,并附加时间锚点与文本上下文,捕捉空间与时间信息。
数据集构建重视“多样性胜于冗余”,通过余弦相似度筛选来自InternVid、Shot2Story、VidChapters等源的高信息量内容,确保语义连贯性与细节注释兼备,使模型能跨时间维度捕捉层次化信息。
性能与基准测试表现
Eagle 2.5-8B在多个视频与图像理解任务中表现稳健:
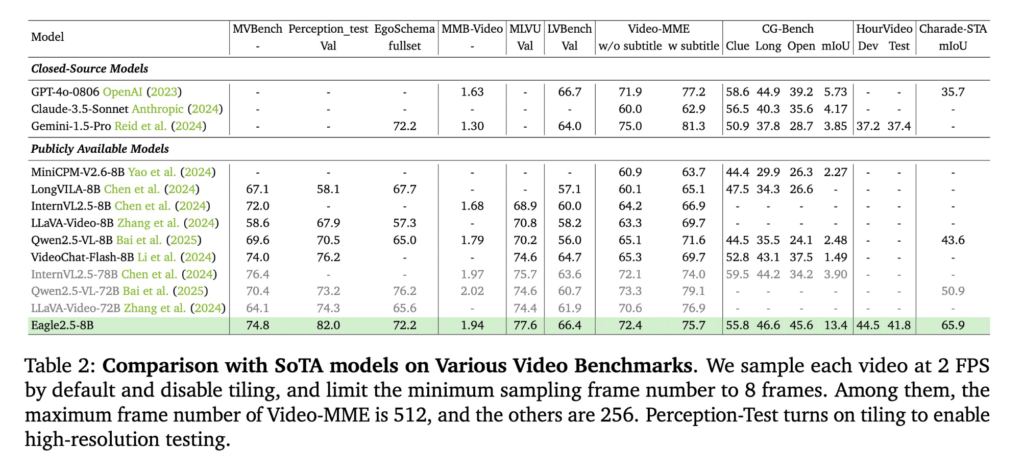
- 视频类任务中,在MVBench得分74.8,在MLVU得分77.6,在LongVideoBench得分66.4;
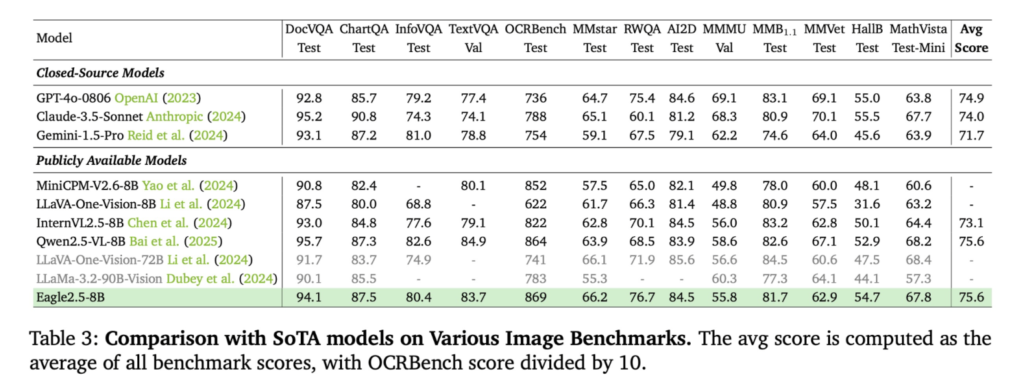
- 图像类任务中,在DocVQA得分94.1,ChartQA为87.5,InfoVQA为80.4。
消融实验验证了采样策略的重要性:去除IAP会导致高分辨率图像理解任务性能下降,去除ADS则影响对密集监督任务的表现。同时,渐进式训练策略表现优于单次长上下文训练,提供更稳定的性能提升。此外,Eagle-Video-110K在帧数超过128的场景中显著提升表现,凸显长篇视频数据集的价值。
结语
Eagle 2.5通过一系列技术基础扎实的方法,推进了长上下文视觉语言建模的发展。其在保持架构通用性的前提下,强调上下文完整性保留、训练节奏适配与数据多样性,使模型在不依赖参数规模扩张的情况下,也能实现高度竞争力与效率兼备的性能。此举标志着向更具上下文感知能力的AI系统迈出了关键一步,为真实世界的多媒体应用提供坚实支撑。