
Lyft每天运行着数亿次机器学习预测,这些并非后台批处理任务,而是实时、关键决策型推理,贯穿于平台的方方面面——从价格预测到欺诈识别,从ETA预估到司机激励分配。
每次推理操作都承受着严格的性能压力,响应预算以毫秒计。系统每秒需处理数百万请求,多个工程团队各自推送模型更新,彼此依赖却也需独立。这对平台灵活性与可控性提出了极高要求。
Lyft将实时ML系统的挑战归结为两类:
- 数据平面压力(Data Plane):涉及CPU、内存、网络瓶颈、推理延迟与吞吐上限。
- 控制平面复杂性(Control Plane):涵盖模型的部署、回滚、版本管理、实验、权限隔离等工程管理难题。
一、为什么Lyft选择自建推理平台?
早期,Lyft依赖一个共享的单体服务统一托管所有ML模型。虽然最初便于启动,但很快暴露问题:
- 各团队无法独立升级依赖;
- 部署互相干扰;
- 一个小模型的更改可能影响整个系统;
- 故障排查如同“破案”。
于是,Lyft决定构建LyftLearn Serving:一个具备高性能、强隔离、面向团队设计的微服务推理平台。
二、系统架构与关键组件
LyftLearn Serving 并未从零重建基础设施,而是在现有微服务架构上演进,融入Kubernetes、Envoy等已有生产组件。每个团队运行自己的一套服务实例,实现部署自主、行为可控、代码独立。
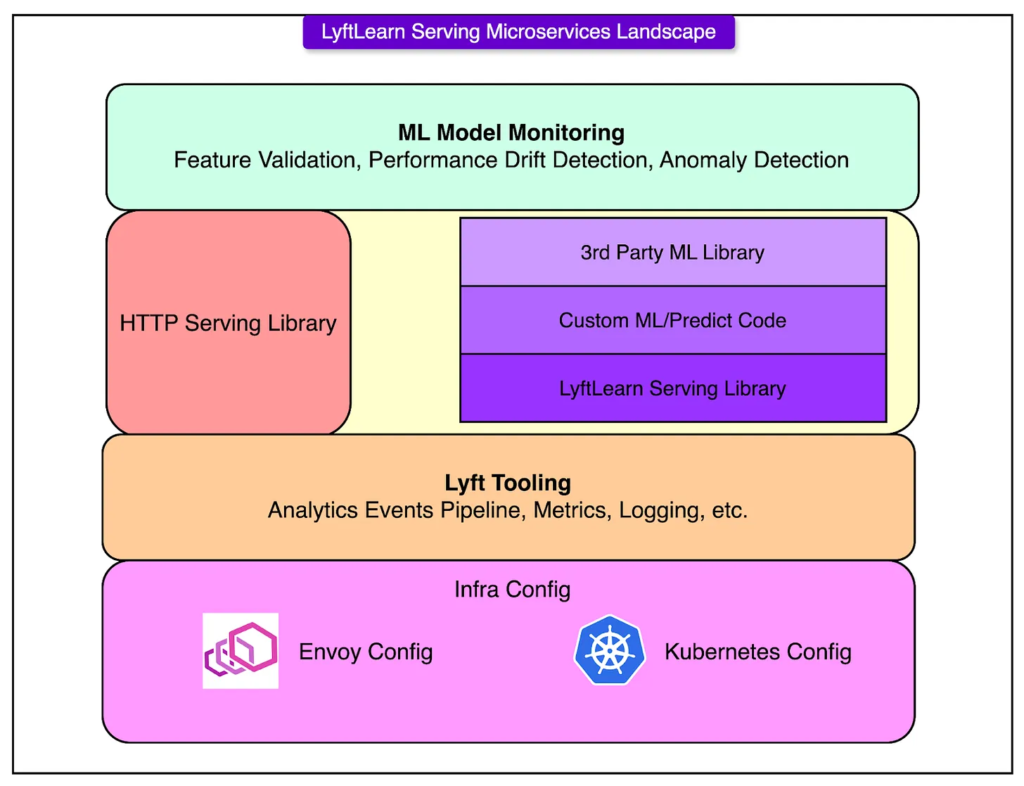
架构流程图核心组成如下:
1. HTTP服务层
每个推理请求首先到达Flask构建的HTTP端点,通过Gunicorn进行高并发管理。其前端由Envoy服务网格处理路由、连接与负载。
优化目标包括:
- 高并发下保持低延迟;
- 平滑的请求接力(Envoy → Gunicorn);
- 抵御网络抖动带来的失败。
2. 核心推理库(Core Serving Library)
这是系统逻辑的核心,负责:
- 模型加载与释放;
- 多版本管理与回退;
- 并行影子部署(Shadowing)测试;
- 日志、指标与链路追踪;
- 输出记录用于调试与分析。
此库为所有团队共享,封装基础能力,但允许完全自定义推理逻辑。
3. 自定义推理代码
每个团队需实现以下两个函数:
pythonCopyEditdef load(self, file: str) -> Any:
# 加载模型对象
...
def predict(self, features: Any) -> Any:
# 推理逻辑
...
这种设计使团队可自由使用任意模型框架(如TensorFlow、PyTorch、LightGBM、XGBoost等),前提是能通过Python接口加载和预测。
4. 基础设施深度集成
LyftLearn Serving 完全集成Lyft的生产基础设施:
- 日志、指标、追踪接入公司级可观测系统;
- Kubernetes实现服务编排与自动扩缩容;
- Envoy服务网格确保服务安全、可发现。
三、“一服务一团队”原则:隔离即稳定
LyftLearn Serving坚持“硬隔离”设计:
- 每个团队一个GitHub代码库;
- 每个仓库定义完整的服务生命周期(代码、部署配置、监控集成);
- 自带CI/CD流程,完全不依赖其他团队;
- 出现部署故障仅影响本团队,不会波及其他服务。
Kubernetes与Envoy提供运行时资源隔离,保障故障局部化。
四、工具支持:从0到部署无需手动配置
Lyft提供“配置生成器(Config Generator)”工具:
- 基于Yeoman定制;
- 引导式交互完成配置生成;
- 自动生成包含load/predict模板的Git库;
- 预集成CI、日志、部署脚本与监控。
新团队可快速生成微服务,几分钟即可上线模型推理服务。
五、模型自测系统:让预测行为可验证
LyftLearn Serving引入模型内嵌测试机制,防止模型部署后出现“性能漂移”或不可预期行为。
每个模型需定义一组最小测试数据集(canary examples):
pythonCopyEditclass SampleModel(TrainableModel):
@property
def test_data(self) -> pd.DataFrame:
return pd.DataFrame([
[[1, 0, 0], 1],
[[1, 1, 0], 1]
], columns=["input", "score"])
测试触发点:
- 部署时自动执行,校验当前环境是否匹配;
- Pull Request中运行CI,防止不显著代码更动带来的预测结果变更。
六、推理请求生命周期:从HTTP到JSON响应
- 请求进入Flask接口(/infer);
- 模型动态加载,通过
model_id调用对应load()函数; - 输入预处理与验证;
- 执行
predict()函数完成推理; - 日志与监控记录请求与响应;
- 输出打包成JSON响应返回。
整个流程高度优化,确保低延迟、高吞吐与强可观测性。
七、经验总结与平台哲学
LyftLearn Serving并非一蹴而就,而是在真实生产压力下演化而来。总结出的核心经验包括:
- “模型”是多重含义的:数据结构、脚本、API接口都称作“模型”,必须建立明确语义与文档。
- 文档即产品:若团队不能自助完成上手与调试,平台就无法扩展。
- API即契约:一旦模型上线,调用方将持续访问,稳定性是基本要求。
- 权衡必不可少:用户体验与灵活性常常矛盾,需明晰系统目标与受众。
- 为强需求者设计平台:最复杂的需求若被满足,平台自然能支持其他团队。
- 优先选择“无聊”的技术:稳定性、可调试性、可运维性优于潮流与复杂性。
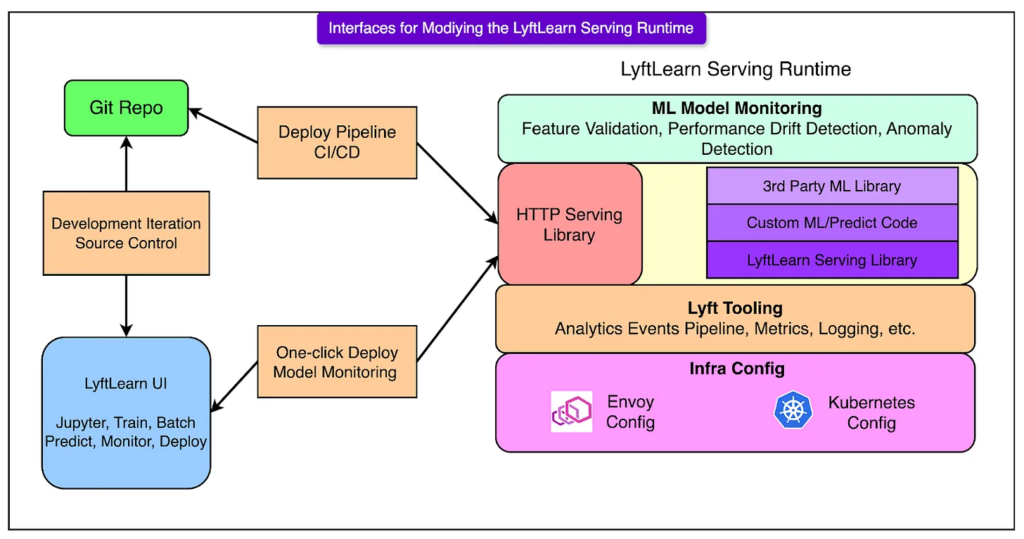
结语
LyftLearn Serving是Lyft为应对高频实时预测构建的一体化推理平台。它的强隔离、高弹性与团队友好性,使数十个工程团队能在生产环境中并行演进、独立部署、稳定运行。正是这一平台支撑起每天超1亿次实时ML推理的业务规模。
它不是隐藏复杂性,而是明确职责边界,保障技术契约,赋能高效迭代。这正是现代大规模AI推理系统所应具备的基础能力。