
谷歌云与加州大学洛杉矶分校(UCLA)的研究团队近日提出一种全新的强化学习框架,可显著提升语言模型在多步骤、高难度推理任务中的表现。这一被称为 监督强化学习(Supervised Reinforcement Learning, SRL) 的方法,将问题求解重新定义为一系列逻辑“动作”,使训练过程获得更丰富的学习信号。
研究表明,SRL 能让规模更小、成本更低的模型掌握以往难以触及的复杂推理能力,不仅在数学推理测试中表现突出,还能有效推广至 软件工程代理任务,展现出跨领域的泛化能力。
研究团队强调,SRL 是一个高度通用的训练框架,可让小模型获得远超其规模的推理能力。
当前大模型推理训练的瓶颈
目前推动大模型推理能力进步的核心方法主要包括:
- 可验证奖励强化学习(RLVR)
- 监督微调(SFT)
其中,RLVR依据最终答案是否正确给予奖励。模型反复尝试解题,在最终对错的反馈中逐渐学会策略。但由于推理“rollout”代价昂贵,模型能尝试的次数非常有限——问题一旦过难,模型往往连一次正确解题都无法“踩中”,导致完全没有学习信号。
更严重的是,复杂推理中模型可能前几步都正确,却在最后一步出错。RLVR 仍给出“错误”奖励,使得模型无法从部分正确的过程学习,这被称为稀疏奖励问题。
另一方向是 SFT,模型模仿专家的详细推理轨迹,但容易过拟合——只会复述训练数据中出现的路径,而非真正理解。同时,高质量专家推理数据极其昂贵与稀缺。
正如论文指出的,现有方法造成了一个严重缺口:
“小型开源模型无法有效学习高难度问题。”
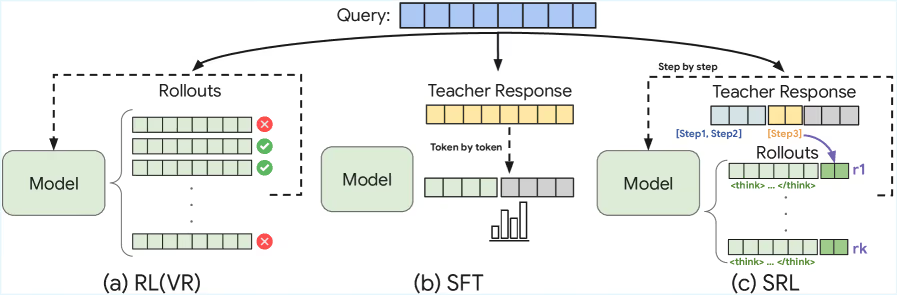
SRL:介于 RL 与 SFT 之间的“中间道路”
SRL 采用一种“顺序决策”框架,在最终结果奖励与全路径模仿之间找到平衡。它不是要求模型只关注最终答案,也不是要求模型逐字模仿专家思路,而是教模型模仿专家推理中的关键动作序列。
专家的完整解题过程会被拆解为一系列具体动作,例如:
- 在数学中:一次代数变形
- 在软件工程中:执行某条代码操作命令
训练数据由更强大的“教师模型”生成,再用于训练较小的学生模型。
Google 研究科学家、论文共同作者许一宏(I-Hung Hsu)指出,SRL 的优势在于贴近现实场景:
“SRL捕捉了真实问题求解的结构化灵活性——有效推理往往有多种路径,但每一步都有明确的好坏标准。这让 SRL 特别适合数据科学自动化或供应链优化等需依赖中间推理质量的领域。”
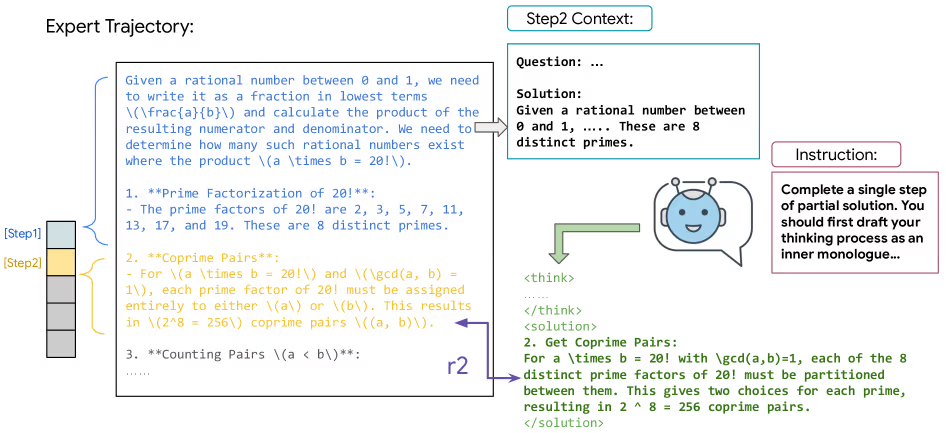
密集奖励训练:模型每做一步动作就获得反馈
在训练时,模型会先产生内部推理“独白”(以 <think> 标签包裹),再做出一个动作。SRL 依据模型预测动作与专家动作的相似程度给出逐步奖励。
这意味着模型即使最终解题失败,也能从部分正确推理中学习,彻底解决了 RLVR 的稀疏奖励困境。
SRL 的实测效果:更强推理、更高灵活性、无额外推理成本
研究中,SRL 在数学推理与软件工程代理任务中均显著优于现有技术。研究者观察到 SRL 训练出的模型更擅长:
- 交替规划
- 自我校验
- 稳健推理而非盲目冗长输出
在推理效率上,SRL 也未显著增加 token 使用量,这意味着更强的推理能力并不以更高成本为代价。
Hsu 强调:
“推理提升来自结构化推理本身,而非输出变长。”
数学推理实验:小模型提升 3% 的平均成绩
研究团队使用 Qwen2.5-7B-Instruct,在 1000 道高难度数学题上进行 SRL 微调,并与 SFT 和 RLVR(使用 DeepSeek-R1 常用的 GRPO 算法)比较。
在四个数学基准上:
- SRL 模型平均领先其他方法 3.0%
- 展现出显著更强的复杂推理能力
软件工程代理实验:SRL 在代码任务上实现 74% 的相对提升
在“智能软件工程代理”测试中,研究团队使用了 Qwen2.5-Coder-7B-Instruct,并使用 5000 条专家轨迹进行训练
与 SWE-Gym-7B(SFT 微调的强力基线)相比,SRL 模型:
- 任务解决率达 14.8%
- 相对提升 74%
结果显示 SRL 尤其适合自动化软件工程这一新兴企业关键领域。
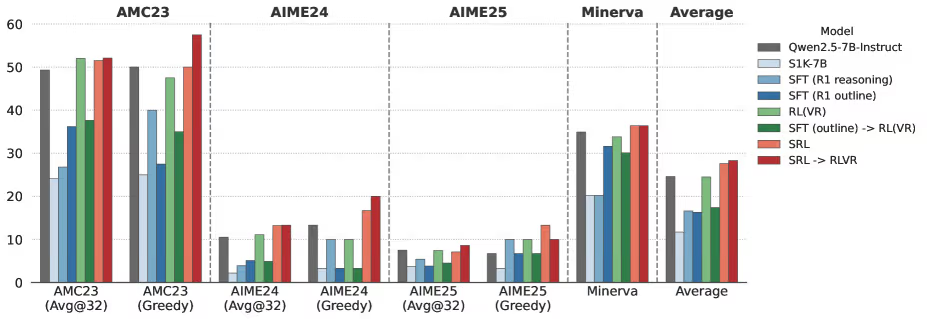
SRL + RLVR:新的高可靠 AI 训练范式?
最强结果来自两阶段训练:
- 先用 SRL 教会模型结构化推理
- 再用 RLVR 强化结果正确性
这种“课程式学习”带来额外 3.7% 的平均提升,被视为构建高可靠性专业 AI 的潜在新标准。
Hsu 指出:
“SRL 为模型提供清晰的推理课程,RL 再进行强化,这使模型在高风险应用中更稳定、更可解释、更具泛化能力。”
未来挑战与展望
尽管 SRL 表现亮眼,但在大型代理任务中整合 RLVR 仍面临:
- 高成本
- 大规模样本生成难度
- 自动化专家数据筛选与生成的工程复杂度
研究团队认为下一步突破点将是:
自动化生成高质量专家轨迹,由强大教师模型或自我迭代学生模型自举数据集。