
在这个人工智能迅猛发展的时代,大型语言模型(LLMs)彻底改变了我们与机器的互动方式,将自然语言理解和生成推向了前所未有的高度。然而,要让这些模型涉足高风险的决策领域,还有一段不小的距离,主要原因在于模型预测的固有不确定性。传统的LLMs递归生成回答,但它们缺乏内在机制来对这些回答进行置信度评分。虽然可以通过累加序列中各个令牌的概率来推导出置信度,但传统方法在可靠区分正确与错误答案上通常不尽人意。但如果LLMs能评估自己的置信度,并只在确信的情况下进行预测呢?
选择性预测正是为此而生,它使LLMs能够输出答案及其正确概率的选择性评分。通过选择性预测,我们可以更好地理解LLMs在各种应用中的可靠性。之前的研究,如语义不确定性和自我评估,已尝试在LLMs中实现选择性预测。一种典型的方法是使用启发式提示,如“提出的答案是真是假?”来触发LLMs的自我评估。然而,这种方法在复杂的问答(QA)任务上可能效果不佳。
以OPT-2.7B模型为例,在TriviaQA数据集的一个问题上给出了错误答案:“哪种维生素有助于调节血液凝固?”,答案是“维生素C”。如果没有选择性预测,LLMs可能输出错误答案,就像这个例子中,可能会导致用户摄取错误的维生素。有了选择性预测,LLMs将输出答案及其选择性评分。如果评分低(0.1),LLMs会进一步输出“我不知道!”来提醒用户不要信任该答案,或使用其他来源进行验证。
在《EMNLP 2023会议发现》中提出的“通过自我评估的适应性改进LLMs中的选择性预测”一文中,我们介绍了ASPIRE——一种精心设计的新框架,旨在提升LLMs的选择性预测能力。ASPIRE通过参数高效的微调,训练LLMs在QA任务中评估其生成答案的正确性,并使LLMs能够输出答案及其置信度评分。我们的实验结果表明,ASPIRE在多种QA数据集上的表现显著优于现有的选择性预测方法,例如CoQA基准测试。
ASPIRE框架的机制
想象一下,如果教会大型语言模型(LLMs)不仅能回答问题,还能评估这些答案——就像学生在教科书后面核对答案一样。这就是ASPIRE的精髓,它包括三个阶段:(1)特定任务的调整,(2)答案采样,(3)自我评估学习。
特定任务的调整:ASPIRE执行特定任务的调整,训练可适应参数(θp),同时冻结LLM。给定一个针对生成性任务的训练数据集,它对预训练的LLM进行微调,以提高其预测性能。为此,可能会采用参数效率高的调整技术(例如,软提示调整和LoRA)来适应任务,因为这些技术在少量目标任务数据下仍能获得强大的泛化能力。具体来说,LLM参数(θ)被冻结,添加可适应参数(θp)进行微调。只更新θp以最小化标准LLM训练损失(例如,交叉熵)。这样的微调可以改善选择性预测性能,因为它不仅提高了预测准确性,还增强了正确输出序列的可能性。
答案采样:在特定任务调整之后,ASPIRE使用学习到的θp的LLM为每个训练问题生成不同的答案,并创建自我评估学习的数据集。我们的目标是生成具有高可能性的输出序列。我们使用束搜索(beam search)作为解码算法来生成高可能性的输出序列,并使用Rouge-L度量来确定生成的输出序列是否正确。
自我评估学习:在为每个查询采样高可能性输出后,ASPIRE添加可适应参数(θs),并仅微调θs来学习自我评估。由于输出序列的生成仅依赖于θ和θp,冻结θ和学习到的θp可以避免在学习自我评估时改变LLM的预测行为。我们优化θs,使得适应后的LLM可以自行区分正确和错误的答案。
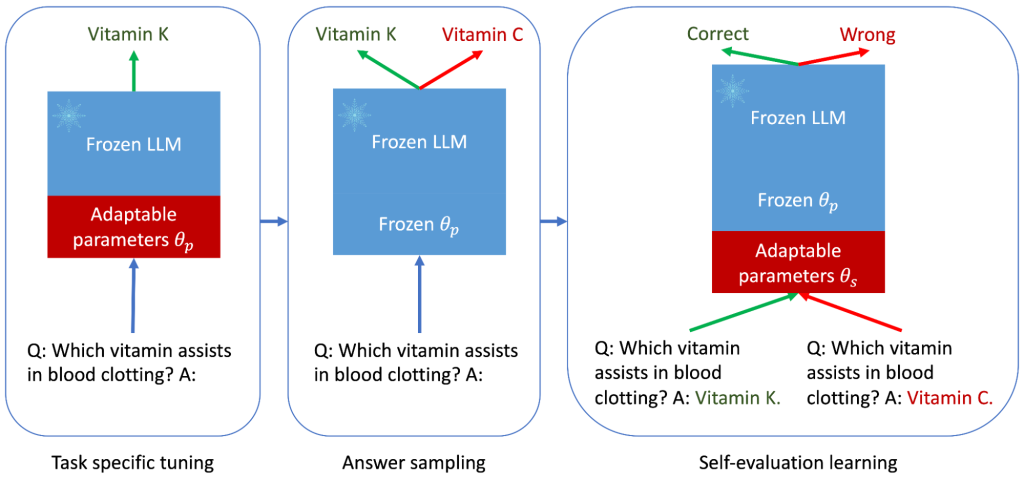
ASPIRE框架的三个阶段。
在提出的框架中,θp和θs可以使用任何参数高效的调整方法进行训练。在这项工作中,我们使用软提示调整,这是一种简单但有效的机制,通过学习“软提示”来使冻结的语言模型更有效地执行特定的下游任务,而不是传统的离散文本提示。这种方法的驱动力在于,如果我们能够开发出有效激发自我评估的提示,那么通过软提示调整结合针对性训练目标,应该有可能发现这些提示。
通过软提示调整实现ASPIRE框架。我们首先使用第一个软提示生成问题的答案,然后用第二个软提示计算学习到的自我评估分数。
训练θp和θs后,我们通过束搜索解码获得查询的预测。然后我们定义一个选择分数,结合生成答案的可能性和学习到的自我评估分数(即预测对于查询的正确可能性),来进行选择性预测。
结果 为了展示ASPIRE的有效性,我们在三个问答数据集——CoQA、TriviaQA和SQuAD——上使用各种开放预训练的变换器(OPT)模型对其进行评估。通过软提示调整训练θp后,我们观察到LLMs准确性的显著提高。例如,使用ASPIRE适应的OPT-2.7B模型在CoQA和SQuAD数据集上的性能超过了更大的预训练OPT-30B模型。这些结果表明,通过适当的调整,小型LLMs可能具有在某些场景中匹敌甚至超越大型模型准确性的能力。
在计算固定模型预测的选择分数时,ASPIRE在所有数据集上的AUROC分数(随机选择的正确输出序列比随机选择的错误输出序列具有更高选择分数的概率)均高于基线方法。例如,在CoQA基准测试中,ASPIRE将AUROC从51.3%提高到80.3%,与基线相比有显著提升。
在TriviaQA数据集评估中出现了一个有趣的模式。虽然预训练的OPT-30B模型展示了更高的基线准确性,但当应用传统的自我评估方法——自我评估和P(True)——时,其选择性预测性能并没有显著提高。相比之下,经ASPIRE增强的较小的OPT-2.7B模型在这方面表现更佳。这一差异强调了一个重要的见解:使用传统自我评估技术的大型LLMs在选择性预测方面可能不如经ASPIRE增强的小型模型有效。
我们对ASPIRE的实验之旅突显了LLMs领域的一个重要转变:语言模型的容量并不是其性能的全部。相反,通过战略性调整,模型的有效性可以大幅提升,甚至在小型模型中也能实现更精确、更有信心的预测。因此,ASPIRE作为一个证明,展示了LLMs能够审慎地确定自身的确定性,并在选择性预测任务中果断地超越大型对手的潜力。
结论 总而言之,ASPIRE不仅仅是另一个框架;它是一个未来的愿景,即LLMs可以成为决策中值得信赖的伙伴。通过提高选择性预测性能,我们正在更接近于实现AI在关键应用中的全部潜力。
我们的研究打开了新的大门,我们邀请社区在此基础上继续建设。我们很高兴看到ASPIRE将如何激发下一代LLMs及其它更多。想了解更多我们的发现,请阅读我们的论文,并加入我们这个令人激动的旅程,共同创造一个更可靠、自我意识更强的AI。