
这篇博客聚焦于NVIDIA H200 GPU在大型语言模型(LLM)、视觉语言模型(VLM)和双塔模型(DiT)推理与训练中的性能表现。当前,SGLang团队正与研究团队共同开展实验,确保结果的可重复性和正式性,并投入了GPU基础设施和工程资源。未来文章将探讨H200的硬件优化及SGLang最新的DeepSeek V3功能改进(如FP8 GEMM优化及H200专属的FusedMoE优化)。
Hopper GPU规格对比:H100与H200
| 技术参数 | H100 SXM | H200 SXM |
|---|---|---|
| BFLOAT16 | 989.5 TFLOPS | 989.5 TFLOPS |
| FP16 | 989.5 TFLOPS | 989.5 TFLOPS |
| FP8 | 1979 TFLOPS | 1979 TFLOPS |
| INT8 | 1979 TFLOPS | 1979 TFLOPS |
| GPU内存 | 80 GB | 141 GB |
| GPU内存带宽 | 3.35 TB/s | 4.8 TB/s |
相比H100,H200的芯片内存增加了76%(141 GB对比80 GB),内存带宽提升了43%(4.8 TB/s对比3.35 TB/s)。
研究方向
- 探索增加H200芯片内存与增加H100推理并行规模之间的权衡。
- 分析H200在内存带宽提升对自回归解码速率的潜在影响。
- 研究如何利用H200的高带宽内存(HBM)进行KV缓存管理优化。
- 对比单节点与多节点推理中的性能差异(如DeepSeek V3的表现)。
- 探讨FP8量化的好处,分析相较于BF16/FP16的加速比。
LLM推理中的内存分配
1. 模型状态内存
推理过程中主要关注模型参数占用的内存,而非优化器状态和梯度。
2. 残差状态内存
LLM推理中的主要内存开销在于中间状态和激活值,尤其是KV缓存的存储需求。更大的批次和上下文长度会显著增加KV缓存的大小,这通常远超模型参数的内存占用。
基于这些需求,SGLang因其性能导向的设计和易于修改的Python代码被选为本次测试的推理系统,而非vLLM或TensorRT-LLM等其他生产级系统。
DeepSeek V3的性能亮点
H200在极大型Transformer模型(如超过6000亿参数)的运行中展现了强大潜力。即便是像Llama 405B这样的模型,H200无需多节点推理即可运行BFLOAT16,避免了节点间通信的开销。
DeepSeek V3采用Mixture-of-Experts(MoE)架构,支持比传统密集模型更高效的推理扩展。其创新的多头潜在注意力(MLA)改进了KV缓存计算效率。此外,引入的多Token预测(MTP)目标显著提升了模型能力和推测解码效率。
DeepSeek V3还是首个成功实现FP8训练的开源大模型,从而跳过了传统的BF16预训练和后续FP8量化流程。
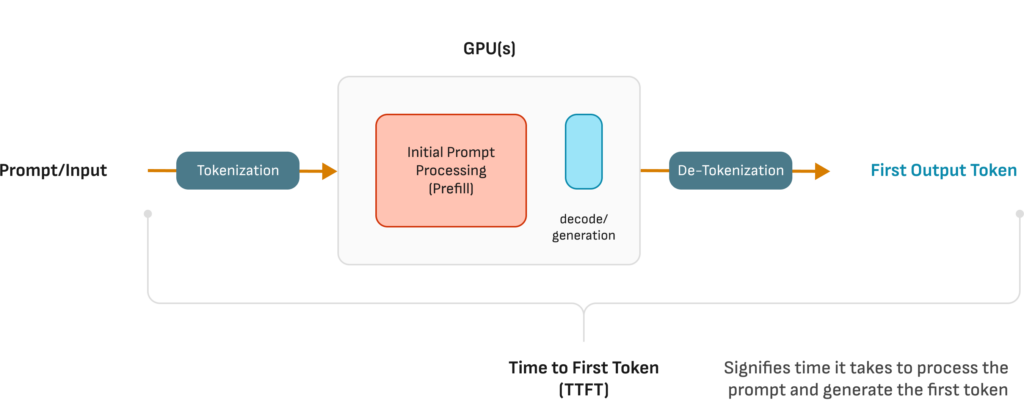
推理性能基准
在本次基准测试中,DeepSeek V3在H200上的性能表现如下:
单节点推理:8×H200
- BF16模式
批次增大时,TTFT(首次Token生成时间)和TPOT(每个输出Token所需时间)表现稳定,随着输出Token吞吐量显著提升。
| 请求速率 | 输出Token吞吐量(tok/s) | 中位TTFT(ms) | 中位TPOT(ms) |
|---|---|---|---|
| 1 | 639.99 | 587.15 | 209.48 |
| 8 | 2249.03 | 1191.74 | 516.67 |
- FP8模式
相比BF16模式,FP8在高请求速率下展现了更高的Token吞吐量和更短的ITL(Token间延迟)。
| 请求速率 | 输出Token吞吐量(tok/s) | 中位TTFT(ms) | 中位TPOT(ms) |
|---|---|---|---|
| 1 | 773.15 | 563.41 | 143.71 |
| 8 | 2864.31 | 1358.77 | 675.95 |
多节点推理:2×8×H200
多节点推理增加了跨节点通信的开销,但仍然展示了大规模批次推理的可行性。
| 请求速率 | 输出Token吞吐量(tok/s) | 中位TTFT(ms) | 中位TPOT(ms) |
|---|---|---|---|
| 1 | 271.60 | 56,824.07 | 862.84 |
| 8 | 276.74 | 1,680,440.41 | 2974.87 |
结论
NVIDIA H200 GPU凭借其显著增强的内存容量和带宽,为大规模模型的推理和训练带来了全新可能性。特别是在需要处理大批次、高KV缓存复用的场景下,H200的表现令人印象深刻。随着针对H200的内核和推理引擎优化的深入,未来性能提升潜力巨大。
测试数据和代码已公开,期待进一步研究推动高性能LLM部署标准的发展。