
Prefix Tuning is one of the coolest Parameter-Efficient Fine-Tuning (PEFT) methods to adapt large language models without retraining the full model. To appreciate how it works, let’s set the stage: traditional fine-tuning involves updating all of a model’s parameters, which is expensive and compute-intensive. Then came prompting — where we steer the model using smart input formatting — and instruction tuning, which teaches the model to follow instructions across a wide range of tasks. More recently, LoRA (Low-Rank Adaptation) became popular by injecting trainable low-rank matrices into model layers, achieving great task adaptation with far fewer parameters.
Prefix tuning takes a different approach: instead of updating the full model or inserting new weights, it learns a small set of prefix vectors that are prepended to the inputs of each transformer layer. This makes it fast, lightweight, and ideal for limited compute setups like Google Colab.
In this blog post, we’ll walk through a step-by-step guide to try prefix tuning using Hugging Face Transformers and peft on Google Colab.
Step 1: Setup Environment on Google Colab
!pip install transformers peft datasets accelerate bitsandbytes
We use:
transformers: for the base modelpeft: for prefix tuningdatasets: to load example datasetsaccelerateandbitsandbytes: to optimize training
Step 2: Load Pretrained Model and Tokenizer
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import get_peft_model, PrefixTuningConfig, TaskType
model_name = "gpt2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
We use GPT-2 here for simplicity. You can swap in other causal models too.
Step 3: Configure Prefix Tuning
peft_config = PrefixTuningConfig(
task_type=TaskType.CAUSAL_LM,
inference_mode=False,
num_virtual_tokens=10
)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
This config adds 10 learnable virtual tokens at each transformer layer. That’s what we’ll tune.
Step 4: Load a Tiny Dataset
For demo purposes, let’s use a small sample of the Yelp review dataset:
from datasets import load_dataset
# Load and sample 1000 examples to avoid fsspec pattern issues
dataset = load_dataset("yelp_review_full", cache_dir="/tmp/hf-datasets")
dataset = dataset.shuffle(seed=42).select(range(1000))
def preprocess(example):
tokens = tokenizer(example["text"], truncation=True, padding="max_length", max_length=128)
return {"input_ids": tokens["input_ids"], "attention_mask": tokens["attention_mask"]}
dataset = dataset.map(preprocess, batched=True)
---
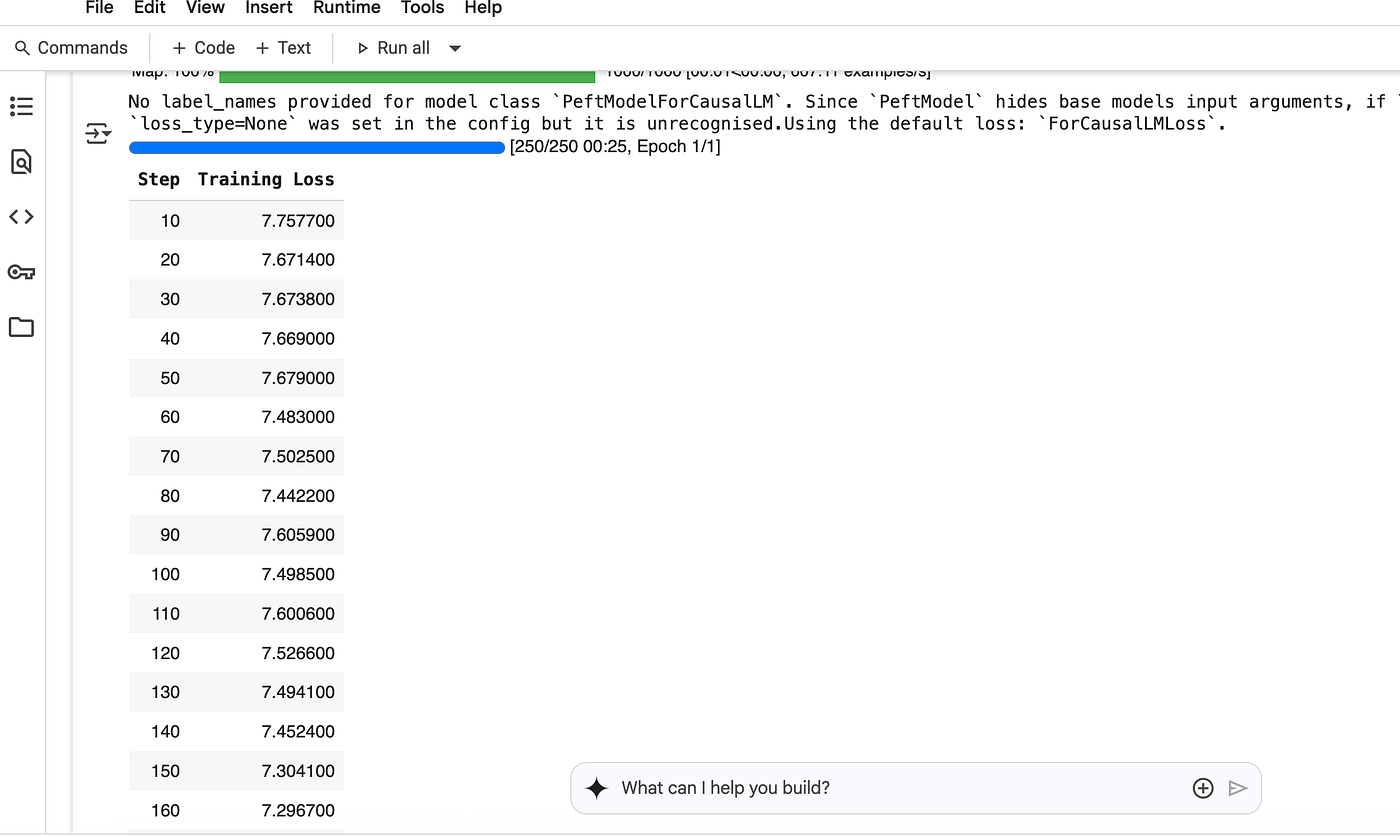
## Step 5: Train with Prefix Tuning
```python
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
output_dir="./prefix_model",
per_device_train_batch_size=4,
num_train_epochs=1,
logging_dir="./logs",
logging_steps=10
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset
)
trainer.train()
Step 6: Save and Load Prefix Adapter
model.save_pretrained("prefix_yelp")
Later, load it like this:
from peft import PeftModel
base_model = AutoModelForCausalLM.from_pretrained("gpt2")
prefix_model = PeftModel.from_pretrained(base_model, "prefix_yelp")
Step 7: Run Inference with the Tuned Prefix
After training, let’s try generating a sample output to see how the model performs with the tuned prefix.
input_text = "This restaurant was absolutely amazing!"
inputs = tokenizer(input_text, return_tensors="pt")
output = prefix_model.generate(**inputs, max_new_tokens=50)
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
print("
Generated Output:\")
print(generated_text)
This should now generate output aligned with your prefix tuning (Yelp-style tone).
Full Code
Here is the complete runnable code for your Google Colab notebook:
# Step 1: Setup Environment
!pip install -U fsspec==2023.9.2
!pip install transformers peft datasets accelerate bitsandbytes
# Step 2: Load Pretrained Model and Tokenizer
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import get_peft_model, PrefixTuningConfig, TaskType
model_name = "gpt2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token # Set pad token
model = AutoModelForCausalLM.from_pretrained(model_name)
model.config.pad_token_id = tokenizer.pad_token_id
# Step 3: Configure Prefix Tuning
peft_config = PrefixTuningConfig(
task_type=TaskType.CAUSAL_LM,
inference_mode=False,
num_virtual_tokens=20 # Increased for better expressiveness
)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
# Step 4: Load and Preprocess Dataset with Labels
from datasets import load_dataset
# Workaround for fsspec issue
try:
dataset = load_dataset("yelp_review_full", split="train[:1000]")
except:
dataset = load_dataset("yelp_review_full")
dataset = dataset["train"].select(range(1000))
def preprocess(examples):
tokenized = tokenizer(
examples["text"],
truncation=True,
padding="max_length",
max_length=128
)
# Create labels for causal LM (same as input_ids, with padding ignored)
tokenized["labels"] = [
[-100 if mask == 0 else token for token, mask in zip(input_ids, attention_mask)]
for input_ids, attention_mask in zip(tokenized["input_ids"], tokenized["attention_mask"])
]
return tokenized
dataset = dataset.map(preprocess, batched=True, remove_columns=["text", "label"])
# Step 5: Train with Prefix Tuning
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
output_dir="./prefix_model",
per_device_train_batch_size=4,
num_train_epochs=3, # Increased for better convergence
logging_dir="./logs",
logging_steps=10,
report_to="none"
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset
)
trainer.train()
# Step 6: Save and Load Prefix Adapter
model.save_pretrained("prefix_yelp")
from peft import PeftModel
base_model = AutoModelForCausalLM.from_pretrained("gpt2")
prefix_model = PeftModel.from_pretrained(base_model, "prefix_yelp")
# Step 7: Run Inference
input_text = "This restaurant was absolutely amazing!"
inputs = tokenizer(input_text, return_tensors="pt")
output = prefix_model.generate(**inputs, max_new_tokens=50)
print(tokenizer.decode(output[0], skip_special_tokens=True))
Example Output
Here’s a sample output after 3 epochs of training with 20 virtual tokens:
This restaurant was absolutely amazing!, a the the the the the the the the the the the the the the the the the the the the the the the the the the the the the a., and the way. , and the was
The model begins to mimic a Yelp-style tone but still produces repetition and low coherence. This highlights why prefix size, data volume, and epochs matter. For better results, increase training data, tune longer, or switch to a stronger base model like gpt2-medium.
Final Thoughts
When to Use Prompting, Fine-Tuning, LoRA, or Prefix Tuning
Choosing the right tuning strategy depends on your goals, resources, and task scope:
- Prompting: Best for general-purpose use cases where zero-shot or few-shot inference is enough. Great for quick tests and rapid prototyping.
- Instruction Tuning: Use this when you want a model to follow specific patterns across tasks but still rely on in-context learning.
- Full Fine-Tuning: Ideal when you have lots of labeled data and need maximum accuracy for a single domain. High compute cost.
- LoRA: Great for large-scale adaptations with moderate resources. You get a good balance of quality and efficiency.
- Prefix Tuning: Best when you want modular, lightweight task adaptation, particularly in multi-tenant or resource-constrained environments.
Real-World Use Cases of Prefix Tuning
Prefix tuning has been successfully used in several real-world and research scenarios:
- Customer Support Bots: Companies fine-tune prefixes on support logs so that one shared base model can handle different product lines or languages with task-specific behaviors.
- Multi-lingual Translation: Researchers have trained prefixes for different language pairs using a shared base model to reduce overhead while maintaining performance.
- Persona-based Dialogue Agents: Prefixes are trained to mimic distinct personalities or tones (e.g., friendly, technical, formal), allowing dynamic switching at inference time.
But it’s not a silver bullet. There are constraints to be aware of:
- You need to train one prefix per use case, so scaling to thousands of tasks like ChatGPT isn’t practical
- The task classifier or router becomes essential if you’re serving multiple use cases
- Prefixes work best when the task is well-defined (e.g., summarization, classification, customer response), but less so for complex or multi-turn reasoning
How Big Should Prefix Sets Be?
The num_virtual_tokens hyperparameter controls how many learnable tokens are added per layer. Common sizes:
- 10–20 for classification tasks
- 20–50 for generation-heavy tasks
- Tradeoff: more tokens = better expressiveness, but slower training and inference
Try starting with 10–20 and increase if your outputs feel too generic or underfitted.
Colab is powerful enough to try it out. You can scale this for customer support bots, internal tools, or even personalized AI tutors — just remember to design your routing and use-case scope thoughtfully.
Have fun geeking out!