
CT Foundation(https://github.com/Google-Health/imaging-research/tree/master/ct-foundation)是一个面向3D CT体积影像的基础工具,基于Google在胸部X射线、皮肤病和数字病理学方面的技术,进一步扩展到3D成像领域。近年来,开发人员和研究人员在构建AI应用方面取得了显著进展。Google Research通过提供用于放射学、数字病理和皮肤病学的易用嵌入式API,帮助AI开发者以更少的数据和计算资源训练模型。但这些应用主要集中在2D成像,而实际诊断中,医生通常依赖3D影像做出复杂的判断。以CT扫描为例,这是一种常见的3D医疗成像技术,每年仅在美国就有超过7000万次CT扫描,主要用于肺癌筛查、神经系统急诊评估、心脏和创伤成像,以及异常X光检查后的进一步检查。然而,由于CT影像具有体积特性,比2D X光更复杂、耗时且需要更大计算和存储资源。
通常情况下,CT扫描数据以标准DICOM格式的2D图像序列存储,然后重新组合成3D体积用于观察或进一步分析。Google于2018年开发了一个低剂量胸部CT影像的肺癌检测研究模型,并在之后改进模型,将其应用于多种临床工作流程,并与欧洲的Aidence公司和印度的Apollo Radiology International合作,将模型投入生产。基于多模态头部CT影像的研究,Google早前在Med-Gemini中描述了自动报告生成的研究成果。
基于Google在3D医学影像模型训练方面的经验,以及CT在诊断医学中的重要性,Google设计了CT Foundation,使研究人员和开发者能够更加轻松地构建适用于不同身体部位的CT影像模型。CT Foundation是一个新发布的医疗影像嵌入工具,它可以将CT体积影像输入转化为信息丰富的数值嵌入,用于快速训练模型。此模型仅供研究使用,不可用于患者护理或诊断治疗。开发者和研究人员可申请免费获取CT Foundation API的访问权限。Google还提供了一个示例代码笔记本,展示如何使用公开的NLST数据进行肺癌检测模型的训练。
CT Foundation的工作原理
CT Foundation能够处理DICOM格式的CT体积影像,并生成1,408维的嵌入向量,汇总重要的器官、组织及异常信息。CT Foundation API自动处理原始DICOM图像,将切片排序、合成为体积影像、进行模型推理并返回CT嵌入结果,免去用户的预处理步骤。用户可以将这些嵌入向量用于分类模型(如逻辑回归、多层感知器)训练,在较少数据下实现高性能,同时显著降低计算资源消耗。
CT Foundation基于VideoCoCa(视频-文本模型)设计,该模型从2D CoCa(对比描述生成模型)延伸而来,专为2D图像与文本的高效迁移学习。Google首先训练了一个专用的医学影像2D CoCa模型,将其作为VideoCoCa的基础,再使用轴向CT切片与放射学报告共同训练VideoCoCa模型。
CT Foundation的评估
为测试CT Foundation的实用性和泛化能力,Google在七个分类任务中评估其数据效率,包括头部、胸部和腹盆部的异常检测任务,涵盖脑出血、胸部和心脏钙化、肺癌预测、腹部病灶、肾结石和腹主动脉瘤等。除了肺癌预测和脑出血任务外,其他任务的标签均通过放射学报告自动提取。肺癌预测任务使用了来自NLST的2年内癌症确诊数据,脑出血任务则由放射科医生标注。Google利用不同大小的训练数据集,评估嵌入向量在多层感知器模型上的数据高效性,使用AUC(ROC曲线下面积)作为评估指标,AUC范围为0.0–1.0,其中1.0为完美模型,0.5为随机猜测。
此外,Google还通过一个更通用的任务展示了CT Foundation在工作流应用中的实用性:身体部位分类。该任务目标是识别CT扫描的解剖区域。此任务的评估指标为八种不同检查类型的分类准确性:头/颈部、颈部、脊柱、心脏、血管造影、胸部、腹部/骨盆及四肢。
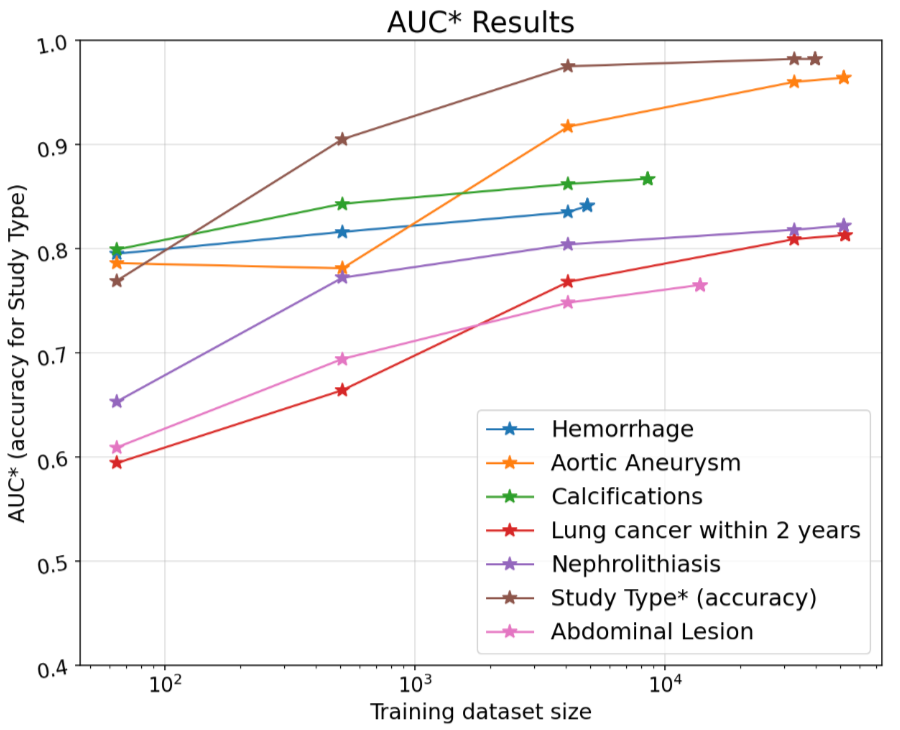
嵌入向量仅1,408维,模型训练仅需CPU即可完成,并可在Colab Python笔记本中操作。即便在训练数据有限的情况下,除一个任务外,其余均能达到超过0.8的AUC。
总结
伴随CT Foundation的发布,Google提供了一个Python笔记本,帮助用户处理CT体积影像,进行模型训练和评估。CT Foundation以其高数据效率和低计算设计,使快速原型开发和研究成为可能,即使资源有限的情况下亦能应用。自动化处理DICOM格式数据的特性,也大大简化了CT建模流程,适合新手和经验丰富的研究人员和开发者。Google期待看到该工具在研究和开发领域的应用,也欢迎社区反馈CT Foundation的性能和应用案例。