
生成式AI是人工智能中的一个重要领域,专注于开发能够生成类似人类文本并解决复杂推理任务的系统。这些模型在自然语言处理等多个应用中至关重要,其主要功能是预测文本序列中的后续单词,生成连贯的文本,甚至解决逻辑和数学问题。然而,尽管这些模型在许多方面表现出色,但在准确性和可靠性上仍存在挑战,尤其是在推理任务中,一个小错误就可能导致整个解决方案的失效。
生成式AI模型的一个显著问题是,它们常常会生成看似自信但实际上错误的输出。这一挑战在对精确性要求极高的领域(如教育、金融和医疗)中尤为关键。模型无法始终生成正确答案,这削弱了它们在高风险应用中的潜力。因此,提升这些AI系统的准确性和可靠性成为研究人员的首要任务,以增强AI生成解决方案的可信度。
为了解决这些问题,目前的方法包括使用判别式奖励模型(RMs),这些模型通过评分来判断潜在答案的正确性。然而,这些方法并未充分利用大型语言模型(LLMs)的生成能力。另一种常见方法是LLM-as-a-Judge,它利用预训练语言模型来评估解决方案的正确性。虽然这种方法发挥了LLM的生成能力,但在需要细致判断的推理任务中,往往不如专门的验证器。
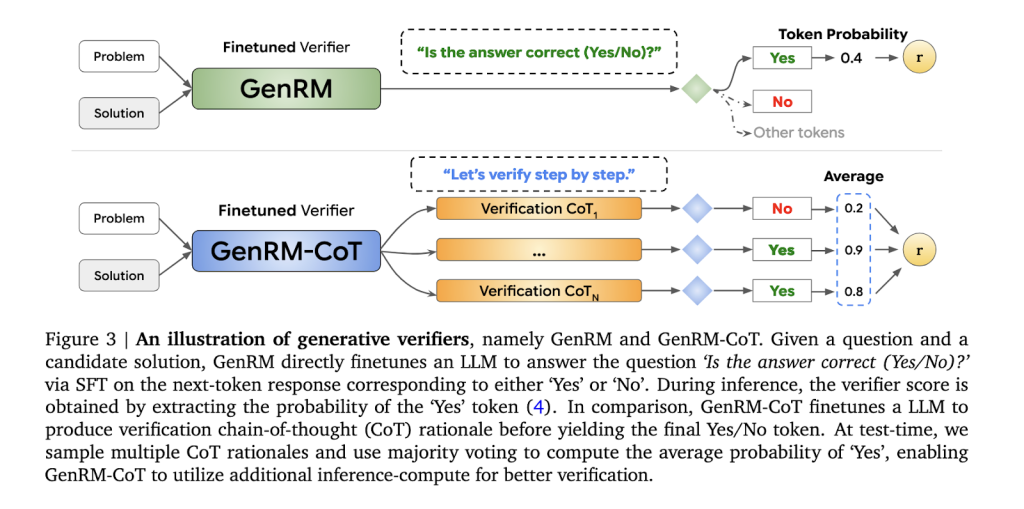
谷歌DeepMind、多伦多大学、MILA和加州大学洛杉矶分校的研究人员引入了一种名为生成式奖励建模(GenRM)的新方法。该方法通过将验证过程重新定义为一个下一词预测任务,充分利用了LLMs的核心能力。与传统的判别式RMs不同,GenRM将LLMs的文本生成优势融入验证过程中,使模型能够同时生成和评估潜在解决方案。这种方法还支持Chain-of-Thought(CoT)推理,模型在得出最终结论前生成中间推理步骤,从而不仅评估了解决方案的正确性,还通过更详细和结构化的评估提升了整体推理过程。

GenRM方法采用了一个统一的训练方法,结合了解决方案生成和验证的过程。通过下一词预测训练模型来预测解决方案的正确性,这种技术利用了LLMs固有的生成能力。在实际操作中,模型会生成中间推理步骤(CoT推理),这些步骤随后用于验证最终的解决方案。这一过程与现有的AI训练技术无缝集成,允许同时改进生成和验证能力。此外,GenRM模型还受益于推理时的额外计算,如通过多数投票聚合多个推理路径,以得出最准确的解决方案。
特别是在与CoT推理结合时,GenRM模型的表现显著超越了传统的验证方法。在一系列严格测试中,包括与小学数学和算法问题解决相关的任务,GenRM模型在准确性上显示出了显著提升。研究人员报告称,与判别式RMs和LLM-as-a-Judge方法相比,正确解决问题的比例增加了16%到64%。例如,在验证Gemini 1.0 Pro模型的输出时,GenRM方法将问题解决成功率从73%提升到92.8%。这一显著的性能提升表明,该模型能够减轻标准验证器在复杂推理场景中经常忽略的错误。此外,研究人员观察到,随着数据集规模和模型容量的增加,GenRM模型能够有效扩展,进一步增强其在各种推理任务中的适用性。

总之,谷歌DeepMind研究人员引入的GenRM方法标志着生成式AI领域在解决推理任务相关验证挑战方面的重大进展。GenRM模型通过将解决方案生成和验证统一为单一过程,提供了更可靠和准确的复杂问题解决方案。这种方法不仅提高了AI生成解决方案的准确性,还增强了整体推理过程,使其成为未来多领域AI应用中的重要工具。随着生成式AI的不断发展,GenRM方法为进一步的研究和发展奠定了坚实的基础,尤其是在精确性和可靠性至关重要的领域。