
在MemGPT中,固定上下文的LLM(大型语言模型)处理器通过分层的内存系统和一套功能得到增强,使其能够管理自己的内存。主上下文是LLM的固定长度输入。在每个处理周期,MemGPT解析LLM的文本输出,并且可以选择放弃控制或执行函数调用,用于在主上下文和外部上下文之间移动数据。当LLM生成函数调用时,它可以要求立即返回执行,以将函数链接在一起。在产生“让步”情况时,除非遇到下一个外部事件触发器(例如用户消息或预定的中断),否则LLM不会再次运行
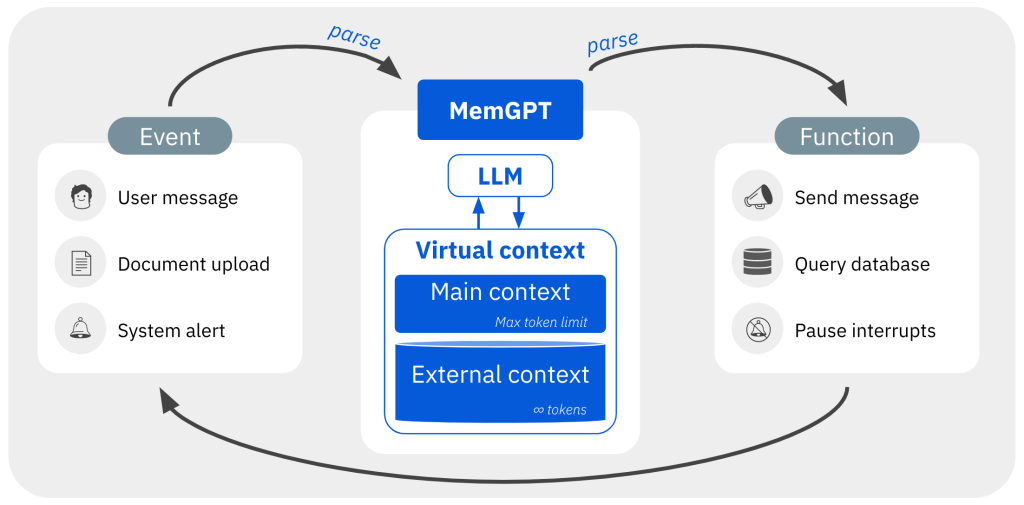
大型语言模型(LLM)在人工智能领域掀起了一场革命,但其受限的上下文窗口在一些任务,如延长对话和文档分析中,限制了其效用。为了克服这一局限,研究人员提出了一种名为“虚拟上下文管理”的技术,其灵感来源于操作系统中的分层内存系统,通过在高速和低速内存之间移动数据,营造出大量内存资源的假象。
基于此技术,研究团队开发了MemGPT(Memory-GPT),这是一种智能管理不同内存层级的系统,旨在在LLM有限的上下文窗口内有效提供扩展的上下文,并利用中断来管理系统与用户之间的控制流。该系统的设计灵感来自操作系统,已在两个领域进行了评估:文档分析和多次会话聊天。在文档分析任务中,MemGPT能够分析大幅超出LLM上下文窗口的大型文档;在多次会话聊天任务中,MemGPT可创建可以记忆、反思,并通过与用户长期互动而持续进化的对话代理。
研究团队在 https://memgpt.ai 网站上分享了MemGPT的代码和实验数据,以便其他研究者和从业者参考和使用。