
今年四月,Meta 曾透露正在研发 AI 领域的一个创新:一个性能媲美 OpenAI 等公司顶尖私有模型的开源模型。
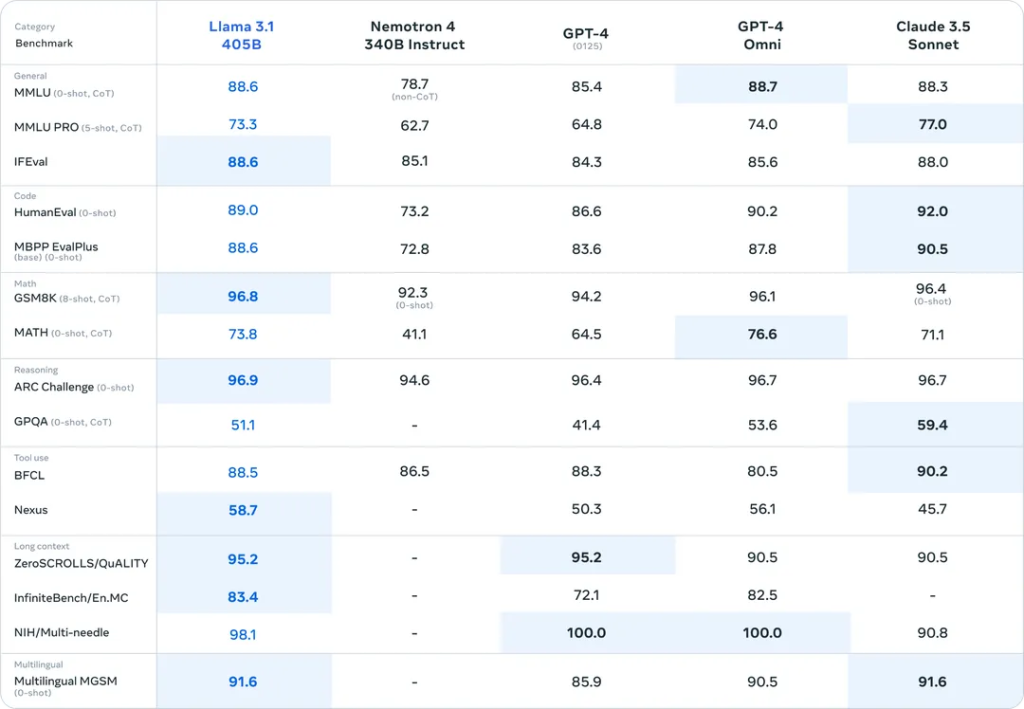
今天,这个模型终于问世了。Meta 发布了 Llama 3.1,这是有史以来最大的开源 AI 模型 ( 下载:https://huggingface.co/collections/meta-llama/llama-31-669fc079a0c406a149a5738f)。公司声称,其性能在多个基准测试中超越了 GPT-4o 和 Anthropic 的 Claude 3.5 Sonnet。Llama 3.1 还将 Meta 的 AI 助手扩展到更多国家和语言,并增加了一个可以基于个人相貌生成图像的功能。Meta CEO 马克·扎克伯格预测,到今年年底,Meta AI 将成为最广泛使用的助手,超越 ChatGPT。
Llama 3.1 比几个月前发布的较小版本复杂得多。最大的版本有 4050 亿个参数,训练过程使用了超过 16000 台昂贵的 Nvidia H100 GPU。尽管 Meta 没有公开 Llama 3.1 的开发成本,但根据这些 Nvidia 芯片的价格,可以推测成本高达数亿美元。
那么,考虑到高昂的成本,Meta 为什么继续以只需公司拥有数亿用户批准的许可证免费发布 Llama 呢?在 Meta 公司博客上发布的一封信中,扎克伯格认为,开源 AI 模型将超过并且已经比私有模型进步得更快,就像 Linux 成为主导大多数手机、服务器和设备的开源操作系统一样。

扎克伯格将 Meta 在开源 AI 上的投资比作早期的开放计算项目,他表示,通过让 HP 等外部公司帮助改进和标准化数据中心设计,Meta 节省了“数十亿”美元。他展望未来,预期 AI 领域也会出现同样的动态,他写道,“Llama 3.1 的发布将成为行业的一个拐点,届时大多数开发者将主要使用开源。”
为了推广 Llama 3.1,Meta 正与包括微软、亚马逊、谷歌、Nvidia 和 Databricks 在内的二十多家公司合作,帮助开发者部署自己的版本。Meta 声称,Llama 3.1 的运行成本大约是 OpenAI GPT-4o 的一半。公司还发布了模型权重,允许企业根据自定义数据进行训练和调优。
令人意外的是,Meta 对用于训练 Llama 3.1 的数据守口如瓶。AI 公司表示不披露此信息是因为它是商业秘密,而批评者则认为这是为了拖延不可避免的版权诉讼。Meta 透露的是,它使用了合成数据,即由模型生成而非人类生成的数据,以提高 4050 亿参数的 Llama 3.1 和较小的 700 亿和 80 亿版本。Meta 的生成 AI 副总裁 Ahmad Al-Dahle 预测,Llama 3.1 将成为开发者的热门选择,作为“部署较小模型的教师”以更具成本效益的方式运作。
关于行业是否将面临高质量训练数据短缺的问题,Al-Dahle 认为可能会达到天花板,但这可能比一些人预测的要晚。他表示,“我们肯定认为还可以再进行几次 [训练]。”但具体情况难以预测。
Meta 的红队测试首次包括了 Llama 3.1 的潜在网络安全和生物化学应用。Meta 还对模型进行了更严格的测试,因其表现出一些“自主”行为。比如,Llama 3.1 可以结合搜索引擎 API,根据复杂查询从互联网上检索信息,并连续调用多个工具完成任务。另一个例子是它可以根据要求检索并生成美国过去五年售出的房屋数量的 Python 代码并执行。
Llama 3.1 将首先通过 WhatsApp 和 Meta AI 网站在美国上线,接下来是 Instagram 和 Facebook,并增加对法语、德语、印地语、意大利语和西班牙语的支持。
Llama 3.1 最先进的 4050 亿参数模型在 Meta AI 中可免费使用,但在达到一周内未指明的提示次数后,会切换到缩减版的 700 亿模型。Meta 表示,将在评估早期使用情况后提供更多信息。
Meta AI 的图像生成功能还包括一个新功能“Imagine Me”,通过手机摄像头扫描面部,以生成包含用户相貌的图像。这样,Meta 希望避免创建深度伪造机器。公司认为用户希望创建更多类型的 AI 媒体并分享,即使这模糊了真实与否的界限。
Meta AI 也将在未来几周内登录 Quest 头显,取代其语音命令界面。用户可以使用 Meta AI 在头显的透视模式中识别和了解现实世界中的物体。
尽管扎克伯格预测 Meta AI 将成为今年年底前使用最广泛的聊天机器人,但 Meta 尚未公布其助手的使用数据。Al-Dahle 表示,“整个行业在产品市场契合度上仍处于早期阶段”。尽管 AI 已经显得过度炒作,但显然 Meta 和其他公司认为这场竞赛才刚刚开始。