
在信息检索领域,创建能够在不同格式间无缝理解并提取相关内容的系统是一项巨大挑战。当前的大多数检索模型仍然局限于单一模态(仅文本或仅图像的检索),在信息丰富的现实场景中,尤其是视觉问答和时尚图像检索等需要文本与图像结合的应用中,这种限制显得尤为明显。因此,开发一种能够同时处理文本和图像以及其组合的多模态检索系统成为当务之急。多模态检索的主要难点在于实现跨模态理解,并克服各模态中的固有偏差。
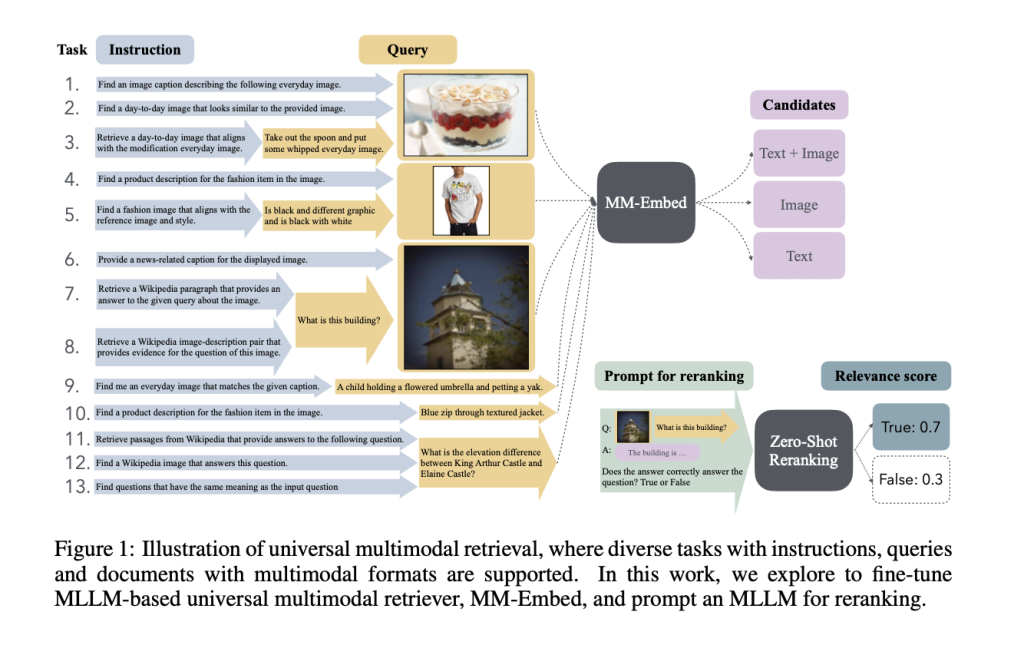
针对这一需求,NVIDIA研究团队推出了MM-Embed,这是一款在多模态M-BEIR基准测试中取得顶级效果的多模态检索模型,并在文本模态的MTEB检索基准测试中跻身前五。MM-Embed致力于弥合多种检索格式之间的差距,使用户在跨越文本和图像内容的搜索中获得更流畅的体验。研究人员将MM-Embed与多模态大型语言模型(MLLM)结合,并作为双编码器在16项检索任务和10个数据集上进行了微调,展示了其广泛适用性。与其他模型不同,MM-Embed不仅支持单一数据类型,还能处理由文本和图像组成的复杂查询。此外,引入模态感知的负样本挖掘技术,有效降低了MLLM中常见的模态偏差,显著提升了检索质量。
MM-Embed的技术实现包括一系列关键策略,以最大化其检索性能。该模型采用双编码器架构,结合模态感知的负样本挖掘,从而更准确地处理混合模态数据。简单来说,这种挖掘方法使模型能够更好地聚焦于目标模态(无论是文本、图像或两者的组合),从而提高应对复杂文本-图像查询的能力。此外,MM-Embed持续进行微调,以提高其文本检索能力,并且不影响多模态任务中的表现。因此,无论是响应有关图像的文本查询,还是根据复杂描述查找相似图像,MM-Embed在各种场景中都表现出色。
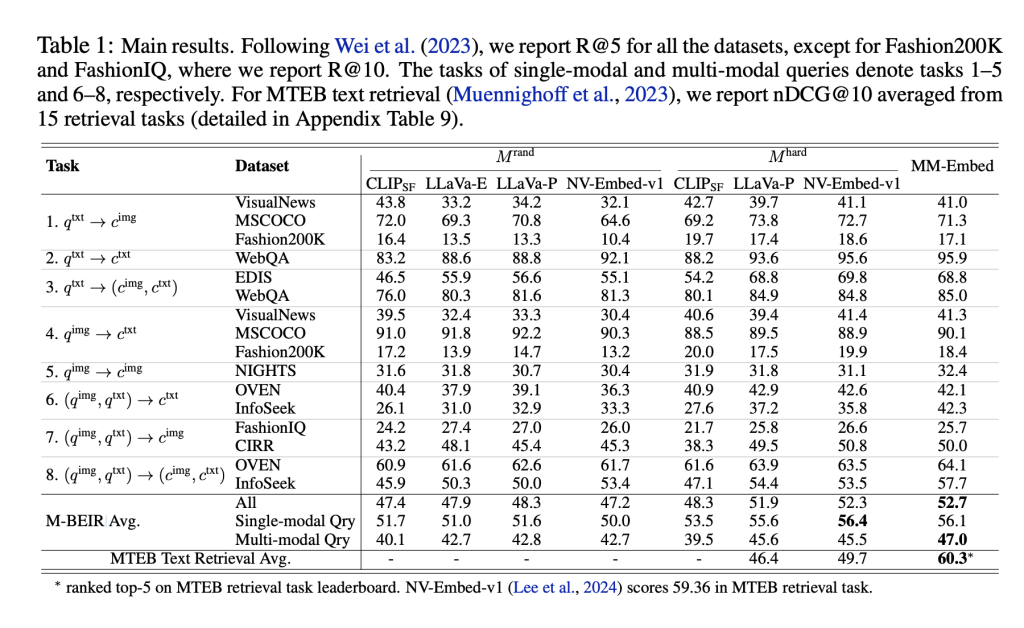
这项进展意义重大。首先,MM-Embed在多模态检索中树立了新的基准,在所有M-BEIR任务中达到了52.7%的平均检索准确率,超越了此前的顶级模型。尤其是在特定领域,MM-Embed表现尤为优异。例如,在MSCOCO数据集上的检索准确率(R@5)达到73.8%,显示出其对复杂图像说明的理解能力。此外,通过零样本重排序,MM-Embed在处理复杂的文本-图像查询(如视觉问答和组合图像检索任务)时进一步提升了检索精度。在CIRCO的组合图像检索任务中,MM-Embed的排名准确率提高了7个百分点,展示了在真实复杂场景中,通过提示LLM进行重排序的有效性。
总的来说,MM-Embed代表了多模态检索领域的重大进步。通过高效整合并提升文本和图像检索能力,它为更灵活、更智能的搜索引擎铺平了道路,使其能够满足现代用户在多样化的数字信息环境中的需求。