
竞赛编程一直以来都是测试编程能力和问题解决技巧的试金石。这类挑战要求选手具备高级算法思维、代码优化能力以及精确执行力,因此也成为 AI 推理能力的重要测试场。虽然 Codex 等早期 AI 模型已经展现出强大的代码生成能力,但它们主要依赖大规模采样和启发式方法,难以真正理解问题并灵活应对。
OpenAI 最新研究突破了这些局限,通过强化学习(RL)大幅提升 AI 在竞赛编程中的推理能力,让 AI 不再只是“拼代码”,而是真正学会如何思考和解决问题。
强化学习 + 竞赛编程:AI 正式进入推理时代
OpenAI 推出的竞赛编程 AI 采用了一种全新的方法,重点在于提升大模型的推理能力,让 AI 在面对复杂问题时能像人类一样分析和优化解法。
研究对比了三种不同模型:
- o1:通用型大推理模型(Large Reasoning Model, LRM)
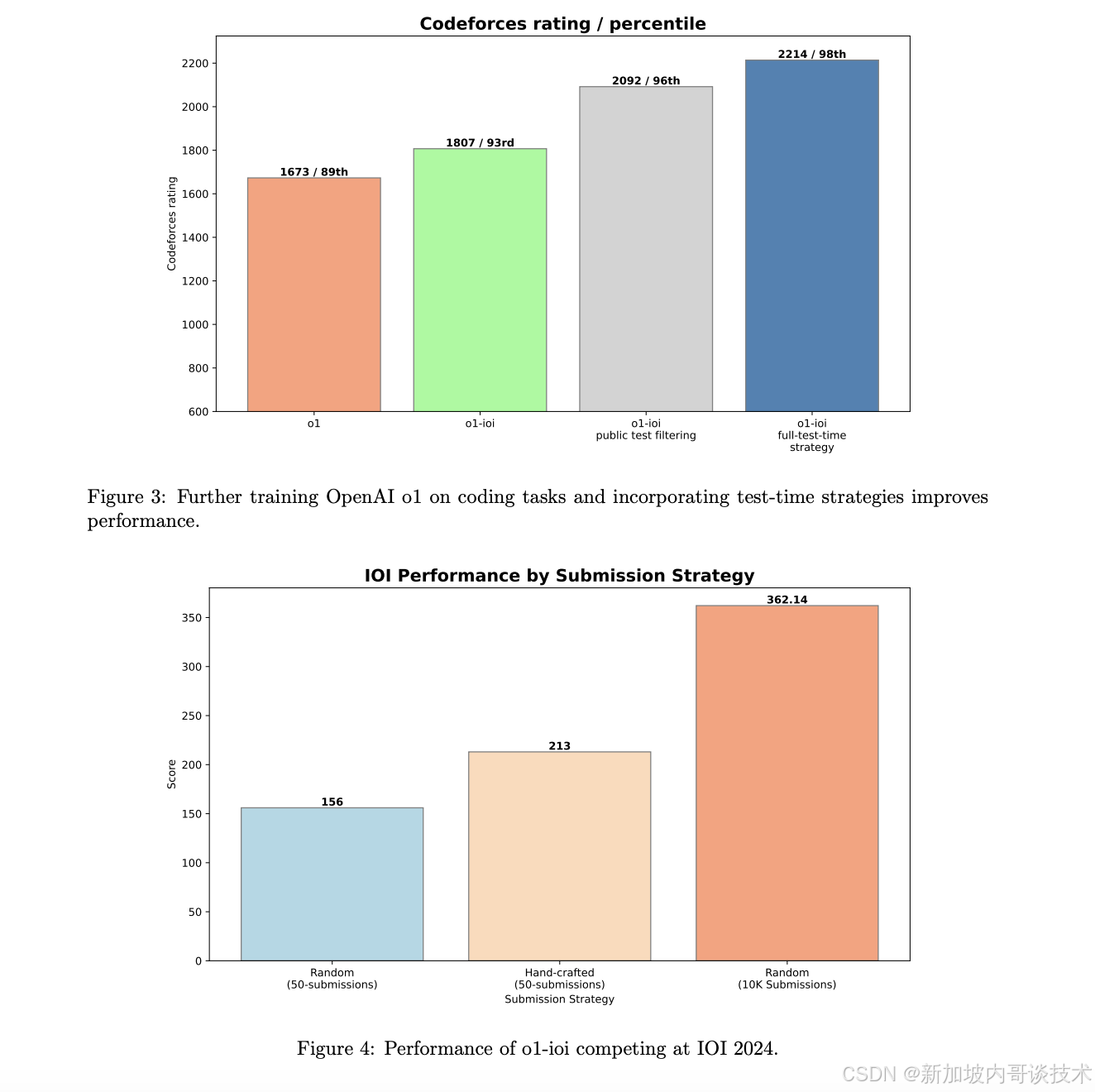
- o1-ioi:专门为 2024 国际信息学奥林匹克竞赛(IOI)优化的模型
- o3:完全不依赖人工设定规则的强化学习 AI
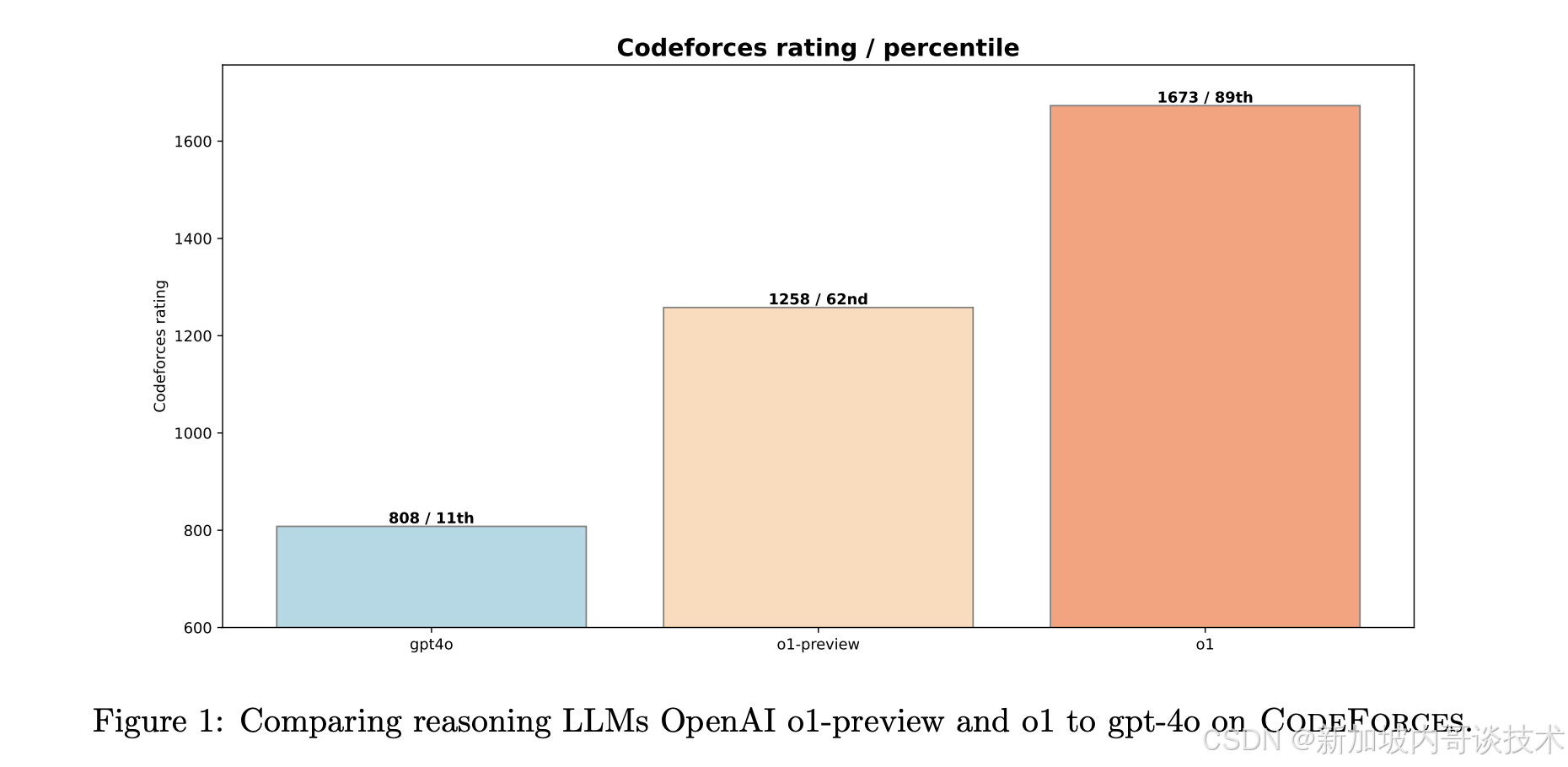
o3 模型的表现最为惊人,在 2024 IOI 竞赛中拿下金牌,并在 CodeForces 竞赛平台上达到了 2724 分,超过 99.8% 的人类选手。这一突破表明,AI 不仅能与顶尖程序员媲美,而且可以完全依靠自我学习来解决问题,而不需要人为干预或特殊优化。
编辑
技术突破:强化学习让 AI 具备真正的推理能力
OpenAI 的竞赛编程 AI 之所以能超越传统方法,核心在于强化学习和推理能力的结合,带来了更智能、更系统的编程能力。相比于过去依赖暴力搜索和手工规则的 AI,这一方法实现了以下关键进步:
- 链式思考(Chain-of-Thought Reasoning)
AI 在解决问题时,会先生成中间推理步骤,而不是直接给出答案。这种方式提高了对复杂问题的理解能力,也让解题过程更加透明。 - 强化学习优化(RL Optimization)
传统 AI 生成代码后无法主动发现错误,而 o3 通过强化学习优化决策过程,可以在编写代码时主动检测和修正错误,提高最终代码质量。 - 自主测试策略(Autonomous Test-Time Strategies)
以往的 AI 在竞赛编程中需要人为设定测试方法,而 o3 能够自主设计验证机制,比如自己写一个暴力破解版本的代码来检查答案是否正确。
相比于 AlphaCode 这样的竞赛 AI 依赖大规模采样和手工筛选,o3 采用强化学习的方式,真正实现了问题理解和自主推理,而不是单纯地“蒙答案”。
竞赛成绩:AI 已迈入顶级人类程序员行列
OpenAI 的研究成果展示了 AI 在竞赛编程领域的重大进展:
- o3 模型在 2024 IOI 竞赛中夺得金牌,成为首个不依赖人工优化就能获胜的 AI 选手。
- 在 CodeForces 竞赛平台上,o3 取得 2724 分,超过 99.8% 的人类选手,比 o1-ioi 这种依赖手工优化的模型表现更强。
- AI 具备自动调试能力,能通过暴力解法自测代码正确性,从而减少 Bug,提高代码质量。
这些成绩证明,强化学习不仅能让 AI 在竞赛编程中超越传统 AI 方法,甚至可以挑战人类编程高手。
编辑
未来展望:AI 的推理能力正在迎来质变
OpenAI 在竞赛编程领域的研究,不仅仅是让 AI 学会写代码,而是让 AI 真正掌握推理和解决复杂问题的能力。
这一突破意味着,AI 的应用前景将大大扩展,不仅在软件开发领域发挥作用,还可能在科学研究、数学推理、自动化决策等高智力任务中展现潜力。
如果这种技术继续进化,AI 将不再是单纯的代码生成工具,而是一个能够独立思考和优化解决方案的智能体。这或许将彻底改变软件开发和人工智能的未来,让 AI 具备前所未有的认知能力。
OpenAI 的这项研究,可能标志着 AI 进入“真正会思考”的时代。