
在自然语言处理(NLP)的迅猛发展中,大型语言模型(LLMs)已展现出卓越的上下文理解、代码生成和逻辑推理能力。然而,当前的模型仍面临关键限制:上下文窗口大小有限。大多数模型的上下文长度上限为12.8万词元,对于需要处理长文档或调试大规模代码库等任务来说,这一限制往往导致开发者不得不采取分块处理等复杂的替代方案,增加了计算成本和技术门槛。解决这一难题需要支持超长上下文且性能卓越的模型。 https://qwenlm.github.io/blog/qwen2.5-1m/
Qwen AI 的最新突破
Qwen AI 团队推出了两款新模型——Qwen2.5-7B-Instruct-1M 和 Qwen2.5-14B-Instruct-1M。这两款模型专为处理高达 100 万词元的超长上下文而设计,并配备开源的推理框架,针对长上下文任务进行了深度优化。它们能让开发者一次性处理更大规模的数据集,极大简化了应用场景中的复杂性,尤其是在分析长文档和代码库时。此外,这些模型集成了稀疏注意力机制和内核优化技术,大幅提升了处理长输入时的速度。

技术细节与创新
Qwen2.5-1M 系列基于 Transformer 架构,采用以下核心技术以支持超长上下文:
- Grouped Query Attention (GQA) 和 Rotary Positional Embeddings (RoPE):提高长距离上下文的稳定性和精度。
- RMSNorm:增强模型在长上下文中的数值稳定性。
- 稀疏注意力方法:例如双块注意力机制(Dual Chunk Attention,DCA),通过将长序列分块处理,提高推理效率。
- 渐进式预训练策略:从4K词元逐步扩展到100万词元,以控制计算成本并提升上下文处理能力。
此外,这些模型兼容 vLLM 的开源推理框架,开发者可轻松集成并部署于实际项目中。
性能表现与优势
在基准测试中,Qwen2.5-1M 系列展示了卓越能力:
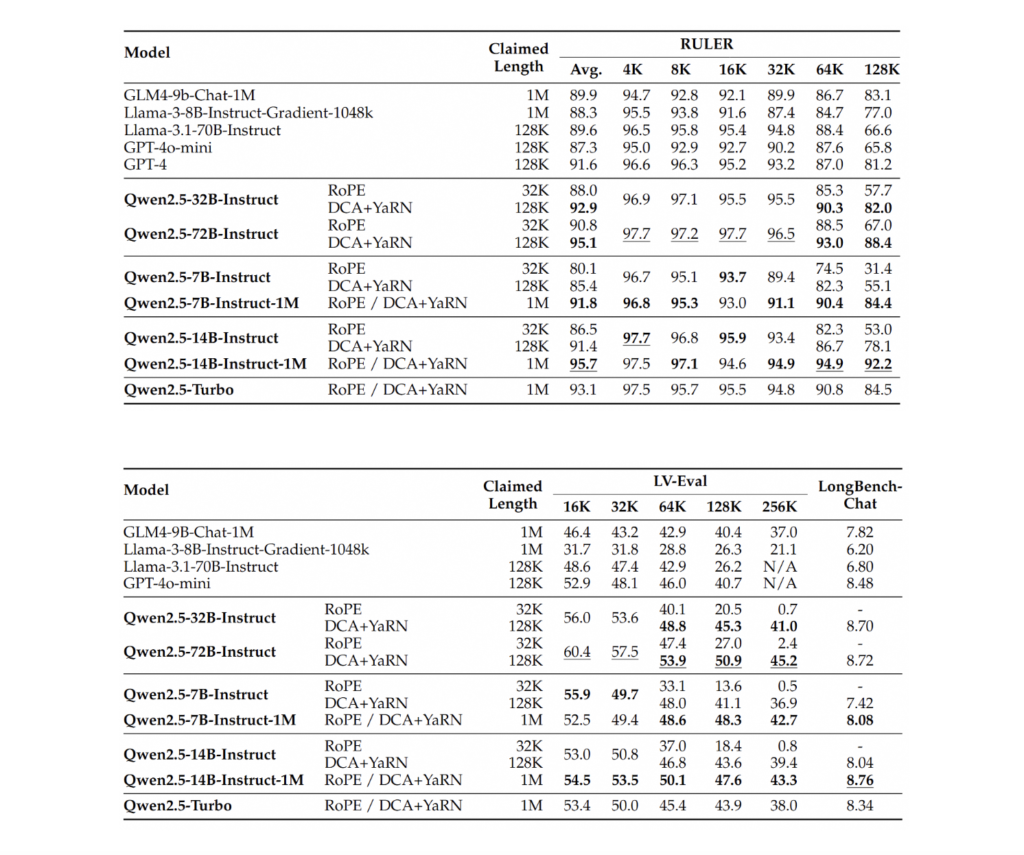
- Passkey Retrieval Test:7B 和 14B 模型成功从包含 100 万词元的上下文中检索出隐藏信息,展现了在长上下文任务中的出色性能。
- 其他测试:在 RULER 和 Needle in a Haystack(NIAH)基准测试中,14B 模型表现优于 GPT-4o-mini 和 Llama-3 等同类竞争对手。
- 效率提升:稀疏注意力技术显著缩短了推理时间,在 Nvidia H20 GPU 上的推理速度提升高达6.7倍。
这些结果表明,Qwen2.5-1M 不仅具有卓越的长上下文处理能力,还兼顾了高效性,适用于现实场景中对上下文要求较高的任务。
开拓 NLP 的新可能性
Qwen2.5-1M 系列通过延展上下文长度并保持高效性,成功解决了长期困扰 NLP 领域的关键瓶颈。无论是分析大规模数据集、处理完整代码库,还是实现复杂上下文推理,这些模型都能为开发者和研究者提供强大工具。凭借稀疏注意力机制、内核优化以及渐进式长上下文预训练,Qwen2.5-1M 系列已成为处理复杂任务的理想选择。
对于需要超长上下文处理的应用场景,Qwen AI 的这一突破无疑将改变游戏规则,引领下一代 NLP 模型的新潮流。