

在过去的一两年中,人工智能领域取得了飞速发展,尤其是在被称为“生成性人工智能”的领域。能像真人一样写作的聊天机器人、图像生成算法以及逼真的语音生成器的演示都已变得司空见惯,并且普通人也能轻易接触到。
这种扩张部分是由大型基础模型(Foundation Models,简称FM)的崛起所推动的——这些庞大的人工智能系统通过从公共互联网上抓取原始数据来接受训练。这些模型通常拥有数百万或数十亿的参数,并且往往具备所谓的“突现行为”(Emergent Behavior)——即执行直接培训之外的任务的能力。因此,它们可以被用于多种应用,作为其他算法的基础。
像许多科技行业内外的人一样,我们对这种快速进展感到印象深刻和兴奋。我们想探索这些模型是如何工作的,以及它们可能如何影响机器人技术的发展。今年夏天,我们的团队开始利用FM为机器人应用制作一些概念验证演示,并在一次内部黑客马拉松中对它们进行扩展。
特别是,我们对使用基础模型作为自主工具的Spot演示感兴趣——也就是说,基于FM的输出实时做出决策。像ChatGPT这样的大型语言模型(LLMs)基本上是非常大而且能力非常强大的自动完成算法;它们接收一系列文本并预测下一部分文本。我们被LLMs表现出的角色扮演、复制文化和细微差别、形成计划以及保持一致性的能力所启发,同时也受到最近发布的可以为图像加标题并回答关于它们的简单问题的视觉问答(VQA)模型的启发。
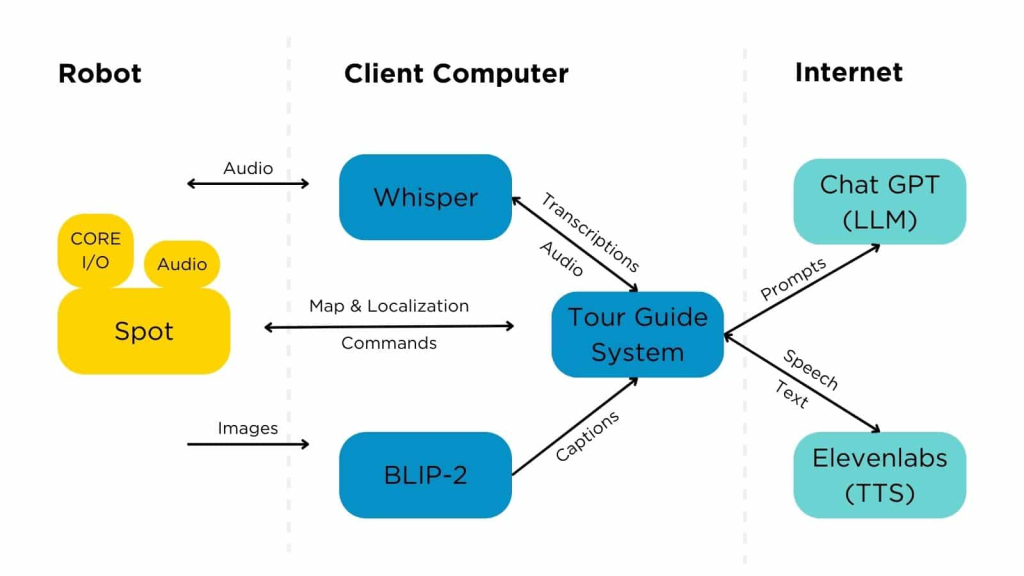

Figure : the hardware setup for the tour guide: 1 – Spot EAP 2; 2 – Respeaker V2; 3 – Bluetooth Speaker; 4 – Spot Arm and gripper camera
通过这个项目,我们找到了一种方法,可以将几个通用人工智能系统的结果结合起来,并利用Spot的SDK在真实的机器人上产生令人兴奋的成果。许多其他的学术界或工业界的机器人小组也在探索类似的概念(更多示例请参见我们的阅读列表)。
我们很高兴能继续探索人工智能和机器人技术的交叉点。这两种技术是完美的搭档。机器人为大型基础模型提供了一个绝佳的方式,使其能在真实世界中得到“落地”。同样,这些模型可以提供文化背景、一般常识知识和灵活性,这对许多机器人任务都可能是有用的——例如,仅通过与机器人对话就能指派任务给它,这将有助于降低使用这些系统的学习曲线。
一个机器人能够通常理解你说的话,并将其转化为有用行动的世界,可能并不遥远。这种技能将使机器人在与人类一起工作时表现得更好——无论是作为工具、向导、伙伴还是表演者。